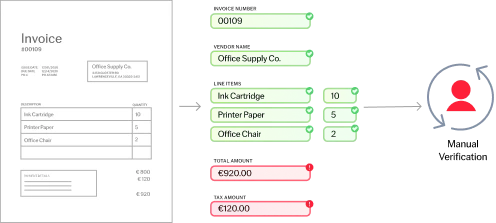
La classification des documents est un processus consistant à catégoriser automatiquement les documents professionnels, avec rapidité et précision, en utilisant l’automatisation pour réduire les erreurs, gagner du temps et optimiser les ressources.
Auparavant, savoir de quel document il s’agissait et où il devait être envoyé nécessitait de déployer beaucoup d’efforts, des programmations complexes ou les deux. Une personne, généralement dotée d’une expertise propre à son secteur d’activité, était mobilisée pour lire chaque email ou parcourir chaque document juridique. Aujourd’hui, de puissants outils d’IA ont complètement changé la donne. Il n’est plus nécessaire qu’un professionnel se penche sur chaque document pour définir qu’en faire. En optimisant le machine learning et des algorithmes de pointe, vous pouvez rationaliser l’ensemble du processus.
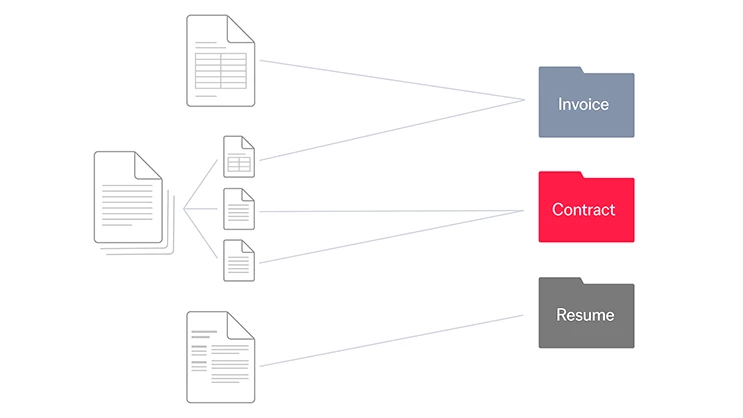
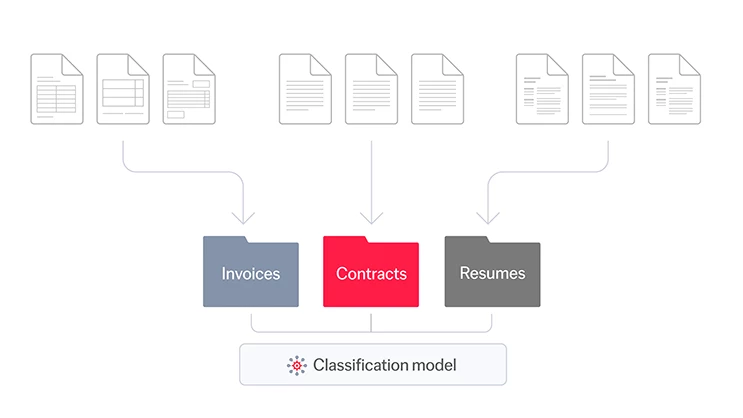
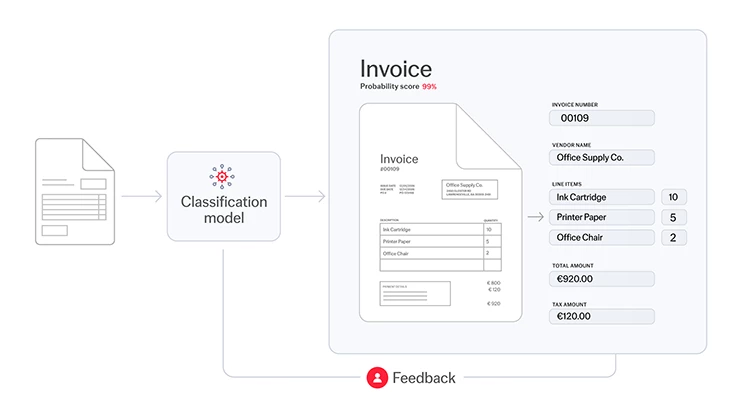
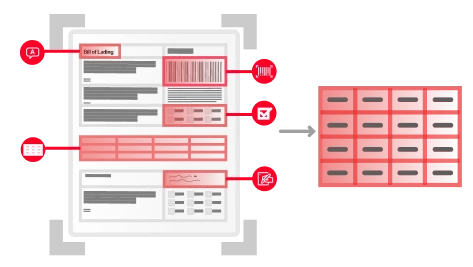
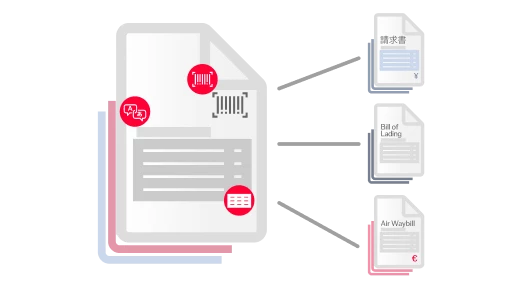
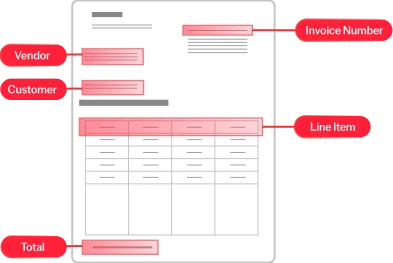
Voici comment le processus se déroule : chaque document qui intègre votre entreprise est scanné par des outils d’IA et analysé, pour être attribué à l’une des catégories prédéterminées. Une fois triés, ces documents ainsi répartis peuvent être acheminés au bon endroit pour un traitement efficace, l’extraction des données ou toute autre action ultérieure.