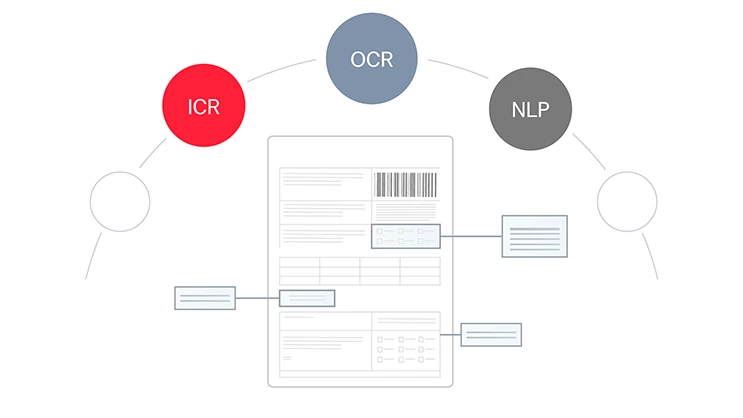
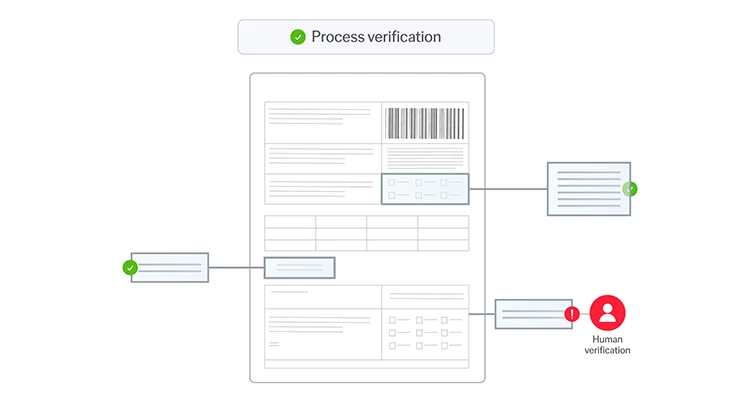
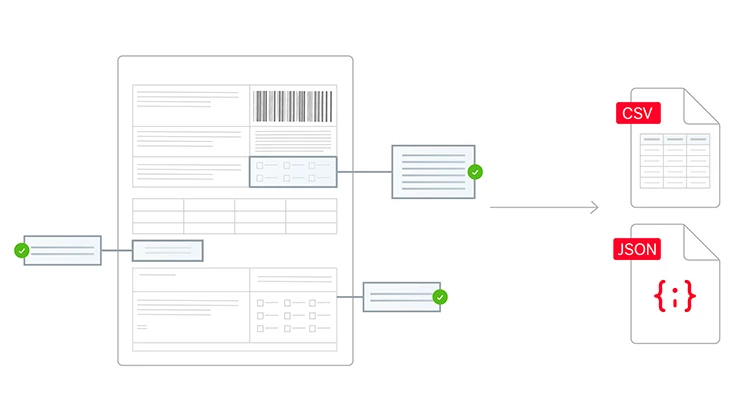
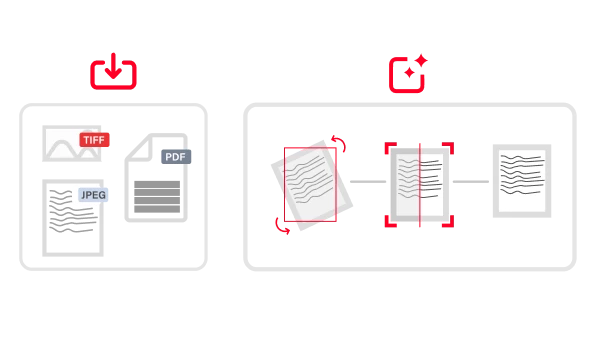
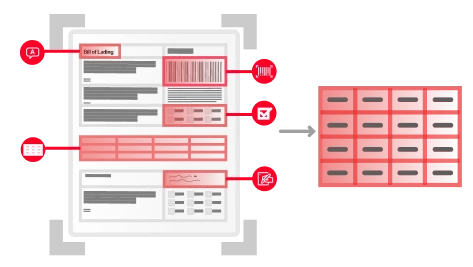
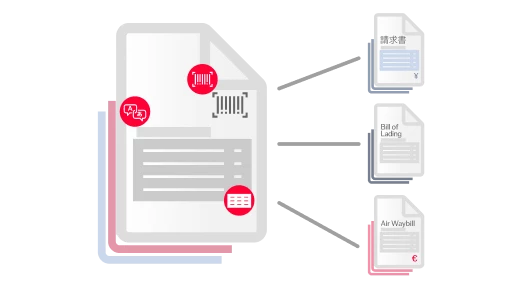
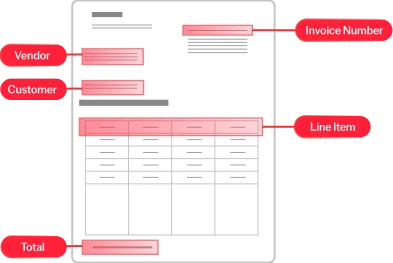
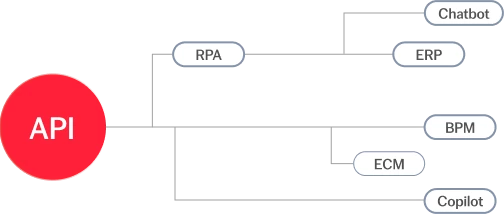
Tout document, toute langue, tout niveau de complexité
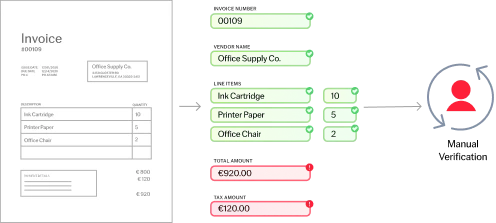
L’IA sur mesure d’ABBYY traite les documents structurés (par ex. des feuilles d’impôts), semi-structurés (par ex. des factures), et non structurés (par ex. des contrats) dans plus de 200 langues. Elle extrait efficacement de documents multipages et de tableaux complexes les données essentielles à votre activité. Cela garantit à votre entreprise des flux de travail fluides et automatisés.