Traitement intelligent des documents (IDP) : fonctionnement, avantages et cas d'utilisation
Maxime Vermeir
25 octobre 2024
Loading component...
Foire aux questions
Quelle est la différence entre l’IDP et l’OCR ?
La différence entre l’IDP et l’OCR réside dans leurs capacités et dans la manière dont ils traitent les données issues des documents.
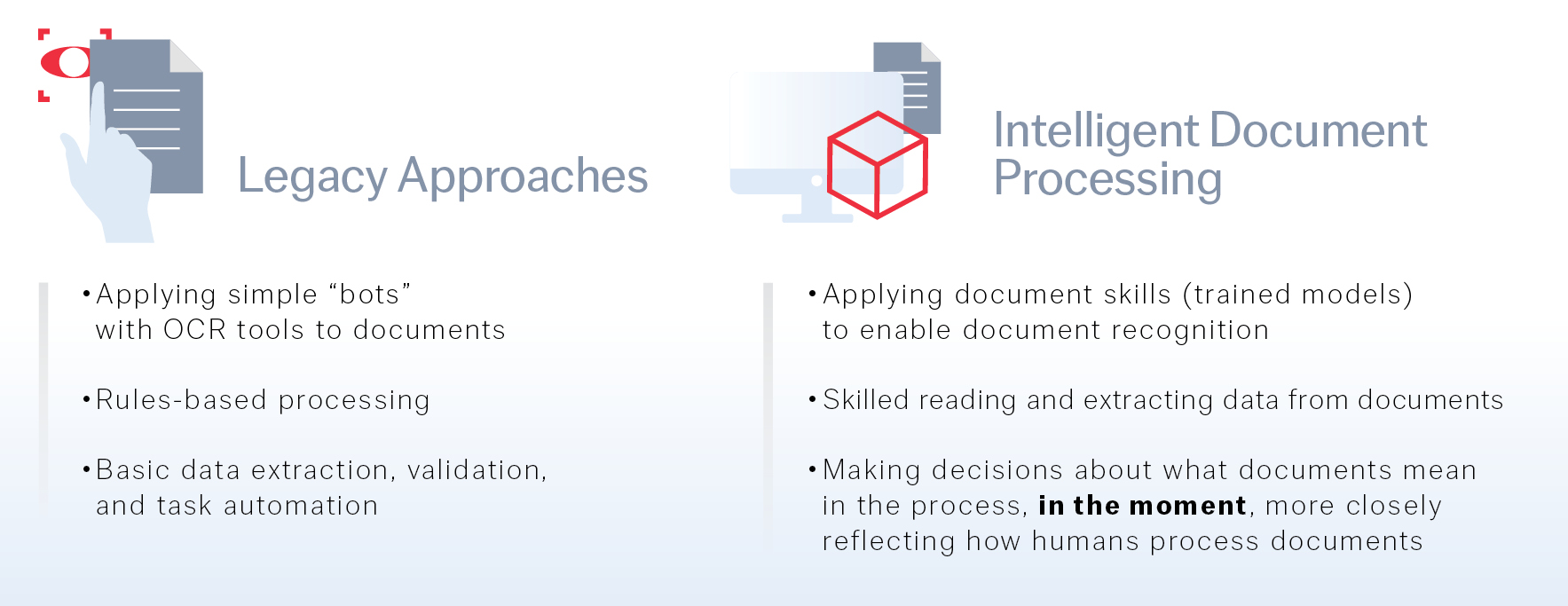
L’OCR existe depuis longtemps et est perçue davantage comme une technologie liée à la capture de données. Elle est avant tout utilisée pour extraire le texte des documents papier, des images scannées ou des photos et le convertir en texte pouvant être modifié sur un ordinateur. Cette technologie est habituellement utilisée pour numériser des documents imprimés et les rendre accessibles de façon électronique, par exemple sur une page web. Cependant, l’OCR ne comprend pas la signification du texte.
L’OCR ne fait que se concentrer sur la reconnaissance de caractères. L’IDP, au contraire, a plus de fonctionnalités. Non seulement l’IDP utilise l’OCR pour reconnaître les caractères, mais il intègre aussi l’intelligence artificielle et le machine learning pour lire le texte et le comprendre afin de pouvoir évaluer sa valeur et de savoir qu’en faire. Par exemple, il peut lire une facture, en extraire le contenu pour le comparer au bon de commande correspondant, comparer les montants pour en vérifier la justesse, puis la transmettre à la bonne personne pour effectuer le paiement.
Quelle est la différence entre le traitement intelligent des documents et le traitement automatisé des documents ?
Pour le dire simplement, l’ADP (Automated Document Processing) est bien moins intelligent que l’IDP. L’ADP peut prendre en charge des tâches routinières et répétitives en lien avec des documents, comme leur tri par ordre alphabétique, l’extraction et la validation des informations. Mais, habituellement, il adopte une approche basée sur des règles et fonctionne mieux avec des documents standardisés ayant la même mise en page. Cela signifie qu’il peut être mis en difficulté par des documents non structurés ou semi-structurés dont le contenu varie et dont la mise en page est différente. Il ne peut s’adapter, ni apprendre du contenu rencontré précédemment.
Le traitement intelligent des documents, lui, utilise l’IA et le machine learning pour traiter un bien plus large éventail de complexités de documents. Il a simplement ajouté des compétences cognitives pour penser comme un humain. L’IDP peut apprendre, s’adapter à différentes mises en pages, à différentes structures et à différents contenus dans les documents et agir en conséquence. S’il est confronté à une légère modification, il saura quoi faire et tirera les enseignements de toute erreur. Cela le rend idéal pour traiter toute donnée non structurée ou lorsqu’il n’y a pas de schéma à suivre, et donc pour les entreprises qui ont affaire à des documents divers et mouvants.
Quelle est la différence entre l’IDP et la RPA ?
L’IDP et la RPA ont tous deux pour objectif d’automatiser les processus métier, mais leurs axes et leurs capacités diffèrent. L’IDP utilise l’IA pour interpréter et extraire des données à partir de documents non structurés ou semi-structurés, en s’adaptant à des formats complexes. La RPA, en revanche, est conçue pour automatiser des tâches répétitives et routinières dans les processus métier, comme la saisie de données, la récupération d’informations et la mise à jour de dossiers dans différents systèmes.
En termes simples, l’IDP s’occupe de l’extraction de données à partir des documents, tandis que la RPA automatise les tâches répétitives. Les deux se complètent en automatisant différentes parties des flux de travail des entreprises.
Quels sont les avantages de l’association de l’IDP à la RPA ?
La RPA est un logiciel traditionnel d’automatisation des processus métier simples et répétitifs. On qualifie souvent cette approche de « chaise pivotante » de l’automatisation, car elle peut effectuer des tâches basiques comme la saisie et la capture des données, la validation des informations, et la mise à jour de documents.
Ce qui manque à la RPA, c’est la capacité à comprendre les informations qu’elle utilise et à les remettre en contexte. C’est ici que l’IDP entre en jeu.
Le traitement intelligent des documents donne à la RPA les compétences cognitives qui donneront du sens aux données lues, ce qui peut déverrouiller des informations cruciales pour les entreprises, afin de prendre de meilleures décisions professionnelles. En associant les deux, vous ajoutez une compréhension proche de celle des humains à l’automatisation de vos processus, pour créer des solutions d’automatisation plus intelligentes et plus efficaces qui stimuleront l’excellence opérationnelle et la croissance de votre entreprise.
Le traitement intelligent des documents (Intelligent Document Processing - IDP) remonte au développement des premières solutions d’OCR (reconnaissance optique de caractères), qui faisaient déjà un peu plus que convertir les caractères sur les images en texte codé par une machine. Aujourd’hui, le traitement intelligent des documents est doté de fonctionnalités basées sur l’intelligence artificielle qui permettent de traiter tout type de données tirées de tout type de documents — structurés, semi-structurés et non structurés — pour à peu près n’importe quel processus dans n’importe quel secteur d’activité.
Ce blog explore les questions que vous posez le plus fréquemment sur le traitement intelligent des documents, y compris sur son fonctionnement, avec des exemples d’utilisation, pour vous donner un aperçu de la façon dont vous pouvez tirer le meilleur de l’IDP pour transformer votre entreprise.
Qu’est-ce que le traitement intelligent des documents (IDP) ?
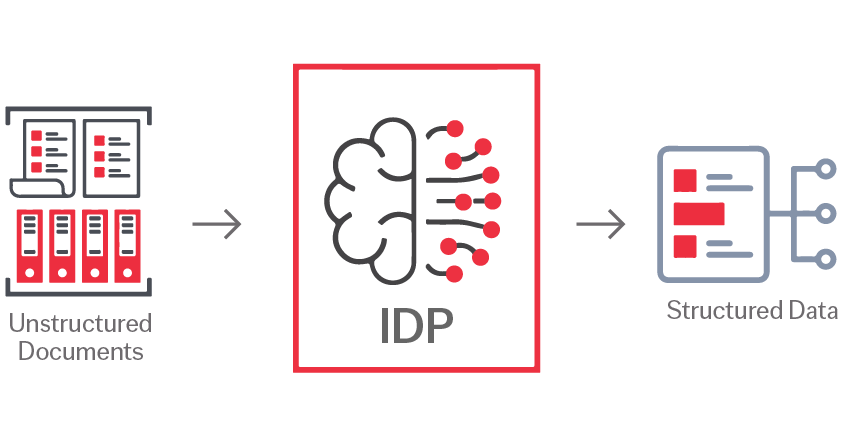
Le traitement intelligent des documents (IDP) utilise l'IA et l'apprentissage automatique pour lire, extraire et organiser les données de n'importe quel document, le rendant ainsi utilisable pour votre entreprise.
IDP fonctionne avec n'importe quel type et format de document (structuré, semi-structuré et non structuré) pour traiter le contenu des documents comme un humain.
Au fil des ans, la technologie a évolué pour y incorporer des fonctionnalités plus intelligentes, telles que le traitement du langage naturel (NLP). Cela a permis au traitement des documents d’aller au-delà de la simple reconnaissance de caractères et d’atteindre un certain niveau de compréhension du texte converti. Mais, malgré ces progrès, pendant des années l’IDP est resté comme une salle isolée ou un BPO, à l’écart des éléments critiques pour le chiffre d’affaires et des engagements avec les clients, les fournisseurs et les salariés.
Aujourd’hui, IDP évolue rapidement. La technologie moderne de traitement intelligent des documents va bien au-delà de la simple extraction de données. Elle repense la manière dont le contenu est utilisé dans les expériences des clients et des employés, en s’appuyant sur des modèles avancés de traitement documentaire basés sur l’IA pour rendre l’information immédiatement disponible et exploitable, exactement quand et où elle est nécessaire.
Quels sont les avantages du traitement intelligent des documents ?
Dans tous les secteurs d’activité, les entreprises subissent la pression de devoir faire plus – et plus vite – avec moins de ressources qualifiées. En même temps, davantage d’entreprises se concentrent sur l’amélioration de l’expérience pour les clients et pour les employés et y voient la clef de l’amélioration de leur chiffre d’affaires, de leurs marges et de la fidélisation. Le traitement intelligent des documents (IDP) présente des avantages importants sur les deux aspects. En utilisant des compétences de document qui s’approchent de la façon dont les humains comprennent et gèrent les contenus, l’IDP offre les avantages suivants :
Efficacité opérationnelle : l’extraction et la saisie manuelles des données peuvent s’avérer chronophages et coûteuses. L’IDP fait gagner du temps/de l’argent tout en limitant le risque d’erreurs coûteuses.
Conformité : l’IDP réduit le risque d’erreur humaine, ce qui signifie que les entreprises sont davantage en conformité. Gérer les tâches de conformité devient plus facile car les « bots » d’IDP laissent une trace numérique et les journaux de bord peuvent être utilisés en cas d’audit.
Expérience client : avec l’IDP, les employés sont libérés des tâches fastidieuses de lecture et de traitement manuel des documents, tandis que les clients profitent d’une meilleure efficacité des processus axés sur les documents et des décisions relatives à leur compte, à leurs demandes ou à leur dossier.
Adaptabilité : l’IDP est ajustable et transverse : un logiciel d'IDP peut être formé pour traiter un type de document (par exemple : les factures) et traiter seulement 100 documents par jour, de même qu’il peut être formé pour traiter une centaine de types différents de documents (factures, demandes, relevés bancaires, inscriptions, reçus, etc.) et traiter des milliers de documents par minute.
Pour comprendre ce qu’est l’IDP et comment il profite aux entreprises, il est tout aussi important de comprendre ce qu’il n’est pas :
L’IDP ne se limite pas à l’OCR ou à la capture de données. Bien que l’IDP intègre la technologie d’OCR et de capture des données, il ne s’agit que d’une partie d’un ensemble plus large de fonctionnalités qui ajoutent plus d’expertise et d’aide à la prise de décision pour traiter le contenu.
L’IDP n’est pas la RPA (automatisation robotisée des processus). La RPA consiste en une automatisation de base des tâches au sein de processus définis qui reposent sur les données. Le contenu étant une source de ces données, il est essentiel de contextualiser ce contenu avant d’en extraire les données pour différents processus en aval. La RPA ne peut le faire seule et il faut donc l’appui de l’IDP pour prendre des décisions pertinentes sur le contenu.
L’IDP n’est pas la même chose que ChatGPT. De nombreuses personnes pensent que ChatGPT est la même chose que l’OCR (reconnaissance optique de caractères), mais ce n’est pas le cas ; en fait, il s’agit d’un modèle de traitement du langage naturel (Natural Language Processing - NLP) qui utilise des algorithmes de deep learning pour générer, sous forme de texte ressemblant à du texte rédigé par un humain, des réponses aux demandes des utilisateurs. ABBYY Vantage, pour sa part, est une solution d’IDP qui utilise la technologie OCR pour extraire les données de différents types de documents, y compris les factures, les bons de commandes, les contrats, et plus encore.
Comment fonctionne le traitement intelligent des documents ?
Décomposons le parcours d’un document à travers le traitement intelligent des documents (IDP).
L’IDP commence par l’entrée des documents. À cette étape, les documents qui arrivent dans votre entreprise via différents systèmes et formats — notes manuscrites, e-mails, fax, photos, et bien plus encore — sont automatiquement collectés.
Ensuite, des outils puissants comme la reconnaissance optique de caractères (OCR) convertissent toutes les informations contenues dans vos documents en texte lisible par machine. Les fichiers peuvent être fractionnés ou prétraités afin d’améliorer la qualité des images, si nécessaire.
Vient ensuite la classification des documents. Le traitement intelligent des documents identifie et classe les documents par type, en fonction de leur contenu et de leur contexte. Grâce au traitement du langage naturel (NLP), il lit le texte et en interprète le sens. Par exemple, est-ce que le mot « jaguar » fait référence à un gros chat ou à une voiture ? Ou bien le mot « Rose » fait-il référence à une personne ou à une fleur ?
Grâce au NLP, un niveau sans précédent de reconnaissance des données non structurées est atteint et les données sont extraites ; cela fonctionne comme un cerveau humain, s’adaptant rapidement à l’évolution des données entrantes et générant les meilleurs résultats possibles.
Une fois les documents classés, l’extraction des données commence. Grâce à la technologie FastML, un mécanisme d’apprentissage côté client, des méthodes visuelles et textuelles d’extraction sont appliquées, ce qui permet d’atteindre une plus grande précision dans l’extraction des données. Cette approche double permet à l’IDP de s’adapter à différents types de documents, mises en page et langues.
Les entreprises qui cherchent à garder un avantage concurrentiel peuvent le faire en laissant de côté la charge de travail fastidieuse, transactionnelle et avec beaucoup de contenu, au profit du traitement intelligent des documents et de solutions intelligentes d’automatisation. Cela dégage du temps pour les salariés qui peuvent alors se consacrer à des tâches plus gratifiantes et offrir une meilleure expérience client.
Exemples d’utilisation du traitement intelligent des documents
La polyvalence de l’utilisation du traitement intelligent des documents signifie que des documents dans n’importe quelle langue, n’importe quel format et à tout moment peuvent être utilisés par des solutions d’automatisation intelligente. Nous allons passer en revue quatre exemples d’utilisation : dans l’assurance, pour l’onboarding client/KYC, dans la logistique et pour le traitement de prêts, ceci afin d’illustrer par des exemples comment l’IDP peut être employé au mieux.
Assurance
Le traitement intelligent des documents dans l’assurance peut être utilisé de nombreuses façons. Par exemple, pour automatiser les décisions comme les règlements de sinistre en « mains libres » ; pour offrir des options intelligentes et numériques en self-service pouvant répondre aux questions habituellement traitées par des call centres ; et pour automatiser les processus numériques, ce qui libérera les employés des tâches routinières et leur permettra de se concentrer sur l’empathie et sur une meilleure expérience client.
Prenons l’exemple d’Ecclesia Group. En utilisant au mieux la solution ABBYY de traitement intelligent des documents, ce courtier international en assurance, a numérisé et rationalisé la gestion de sa correspondance, offrant ainsi une meilleure expérience client. Aujourd’hui, l’IDP extrait les données essentielles des documents d’assurance scannés, y compris les numéros de dossier et les plaques d’immatriculation ; il rapproche correctement les documents des données en lien avec le dossier dans la base de données client ; et il achemine automatiquement le document au gestionnaire approprié, pour traitement.
Services bancaires et financiers
Le traitement intelligent des documents dans les services financiers transforme les processus documentaires liés à l’intégration des clients, à la conformité KYC, au financement du commerce et bien plus encore. Les demandes de prêts hypothécaires sont un excellent exemple de la surcharge de documents puisqu’un dossier de prêt typique compte 100-200 pages. Parmi les pièces nécessaires, il peut y avoir permis de conduire, certificat de naissance, justificatif de domicile, facture de services publics, relevés bancaires, ou fiches de paie. Le traitement intelligent des documents peut optimiser tout le processus en capturant, lisant, comprenant et validant automatiquement les informations contenues dans chaque document, pour vérifier que les données soient justes et authentiques afin que le prêt soit approuvé plus rapidement. L’ensemble du processus peut se faire en ligne et sur mobile pour une expérience client améliorée et plus ergonomique.
Mieux encore : la capacité de l’IDP à s’adapter au surplus de demandes de prêt qui surgissent souvent en période de récession économique. Pendant la pandémie, les banques espagnoles ont eu besoin de traiter le chiffre stupéfiant de 20 millions de pages de documents de la part de clients qui demandaient un prêt – avec des pics atteignant plus de 100 000 pages par jour. Grâce à la technologie ABBYY de traitement intelligent des documents, cela a été fait en moins de 6 semaines pendant le confinement. Serimag, société leader de l’automatisation des processus dans le secteur bancaire en Espagne, a su exploiter au mieux la plateforme IDP d’ABBYY, lui permettant d’extraire rapidement et précisément le texte de millions de demandes de prêts. Résultat : une automatisation de 75% de l’ensemble du processus et un soutien aux efforts de Serimag pour garantir la justesse des SLA dans 99% des cas.
Santé
Les organisations de santé sont confrontées à une pression considérable pour optimiser l’utilisation des services, améliorer la gestion des revenus et réduire les coûts. Un nombre croissant de prestataires de soins de santé se tournent vers l’automatisation intelligente afin de rationaliser leurs processus et d’extraire des informations métier exploitables à partir de leurs processus basés sur les données. Le traitement intelligent des documents (IDP) dans le secteur de la santé les aide à atteindre ces objectifs en fournissant un accès instantané aux données critiques issues de leurs documents, afin de soutenir une prise de décision plus rapide et plus pertinente.
La U.S. Food and Drug Administration a utilisé l’IDP d’ABBYY pour accélérer le traitement des formulaires signalant les effets indésirables des médicaments — contribuant ainsi à une meilleure protection de la santé publique. La plateforme IDP d’ABBYY, basée sur l’IA, a atteint un taux de précision de 99 % dans la capture des informations critiques et leur transmission aux parties concernées.
Transport & Logistique
Des erreurs de paperasserie peuvent stopper des cargaisons en pleine route et entraîner d’importants retards dans la livraison de biens essentiels. Le traitement intelligent des documents dans le secteur du transport et de la logistiqueapporte dans son sillage précision et efficacité opérationnelle, en gérant de façon automatique toute une série de documents d’expédition tels que les formulaires de déclaration en douane, les bons de livraison, les connaissements ou les cartes chauffeur, à tout moment et en tout lieu.
L’entreprise allemande internationale de logistiqueDeutsche Post DHL livre des colis et du courrier express par-delà les frontières, dans le monde entier, et a obtenu des résultats remarquables en automatisant son département Finances. Cette entreprise, qui a généré 100 milliards USD en 2022, avait précédemment un système de comptabilité très manuel pour traiter des centaines de milliers de factures chaque année. En mettant en place le traitement intelligent des documents ABBYY, elle a pu traiter automatiquement les factures de 124 fournisseurs, dans différentes langues — réduisant ainsi les erreurs et gagnant en productivité. Le groupe a ensuite étendu ce projet d’automatisation via l’IDP à d’autres départements pour profiter d’une augmentation incroyable de 70% de son efficience.
Comment le traitement intelligent des documents a-t-il évolué ?
Avant le traitement intelligent des documents, la gestion de l’afflux de documents était une tâche laborieuse et sujette aux erreurs. La saisie manuelle des données et les processus basés sur le papier entraînaient des goulets d’étranglement et des erreurs coûteuses. Les solutions OCR traditionnelles apportaient un certain soulagement, mais manquaient de l’intelligence nécessaire pour réellement comprendre et extraire des informations pertinentes. Les entreprises se retrouvaient confrontées à de grandes quantités de données non structurées, peinant à suivre le rythme des exigences rapides du monde des affaires.
L’IDP, en combinant la puissance de l’OCR avancé et de l’IA, a changé cet état de fait. En intégrant l’apprentissage automatique et le traitement du langage naturel (NLP), les solutions d’IDP peuvent désormais non seulement extraire des données, mais aussi comprendre le contexte, classifier les documents et prendre des décisions intelligentes. Il s’agit d’une avancée majeure qui ouvre une nouvelle ère de précision et d’efficacité.
Quelle est la prochaine étape pour l’IDP ? L’avenir du traitement intelligent des documents est appelé à révolutionner la manière dont les entreprises et les professionnels de l’IT gèrent d’énormes volumes de données, en apportant une valeur encore plus grande aux organisations grâce à :
Des capacités accrues en IA et en apprentissage automatique, permettant de traiter des documents de plus en plus complexes avec une précision et une efficacité toujours croissantes.
L’analytique prédictive, grâce à laquelle les systèmes d’IDP pourront analyser les données historiques et prévoir les tendances et les modèles dans les données documentaires, permettant ainsi aux entreprises de prendre des décisions encore plus éclairées.
Une plus grande personnalisation et flexibilité, permettant aux entreprises d’adapter la solution à leurs besoins spécifiques et rendant l’IDP accessible à un éventail plus large de secteurs et de cas d’usage.
Davantage d’intégrations avec d’autres technologies d’entreprise telles que les systèmes de planification des ressources de l’entreprise (ERP), les systèmes de gestion de la relation client (CRM), l’automatisation robotisée des processus (RPA) et la gestion des processus métier (BPM), permettant des flux de travail fluides et une efficacité opérationnelle encore accrue.
Comment choisir le bon logiciel de traitement intelligent des documents
Avec tellement de bruit autour de l’intelligence artificielle et un paysage technologique en constante évolution, choisir le bon logiciel de traitement intelligent des documents est une décision capitale pour vous assurer d’être sur les bons rails, pour une transformation numérique optimale de vos processus métier. Voici quelques points essentiels à prendre en compte.
1. Évaluez les besoins précis de votre entreprise.
Il n’existe pas d’approche unique qui conviendrait à tout le monde. Vous devez donc bien réfléchir à vos besoins spécifiques. Quels résultats voulez-vous précisément obtenir ? Une meilleure expérience client, une amélioration de la productivité, un traitement direct et sans contact, une baisse des burnouts chez les salariés ? Les objectifs de votre investissement dans l’IDP doivent être précisés dès le départ pour être sûr que vous choisirez la bonne plateforme, au bon prix, et obtiendrez un bon retour sur investissement (ROI).
Dressez une liste détaillée de questions à votre potentiel fournisseur en termes de résultats attendus, d’accroissement de la productivité, de facilité d’intégration, de prise en main par l’utilisateur, d’adaptabilité, de formation du personnel, ainsi que de sécurité et de conformité, en particulier alors que sont introduites de nouvelles lois sur l’éthique de l’IA.
2. Déterminez les données que vous avez besoin de traiter.
Selon votre secteur d’activité, le type de données et de documents que vous aurez à traiter sera différent. Il peut s’agir de la gestion de sinistres dans le secteur de l’assurance, de documents juridiques dans les cabinets juridiques, de demandes de prêts pour les banques ou de gestion de contrats pour les agents immobiliers. Le traitement intelligent des documents peut être personnalisé et formé pour gérer différents types de documents.
Les données nécessaires peuvent être structurées, comme des informations sur des formulaires standard et des tableaux ou des champs correspondants dans la base de données de l’entreprise ou sa plateforme de logiciels. Mais vous pouvez aussi être amenés à traiter des données non structurées comme celles tirées d’emails, de textos ou de graphiques. Certaines peuvent être hautement confidentielles. Il est donc fondamental de savoir où sont les données avec lesquelles vous travaillez et le type de données dont il s’agit avant de choisir votre plateforme IDP.
3. Cherchez une solution répondant à vos exigences.
Une fois que vous aurez défini vos besoins spécifiques, il sera plus facile de trouver une solution répondant à vos contraintes. Par exemple, il se peut que vous ayez des données dans différentes langues, ayant besoin d’être traduites avant d’être analysées ou transmises à un autre système. Il peut y avoir des consignes strictes pour le respect de la vie privée dans l’utilisation des données ; dans ce cas, les fonctionnalités d’authentification et de validation de votre plateforme d'IDP seront une priorité.
L’intégration des données est aussi un élément important pour le transfert automatique vers les workflows existants. L’IDP peut classer les documents en catégories prédéfinies pour organiser et prioriser la charge de travail. Par exemple, il peut trier les demandes par date ou classer les emails dans différents dossiers en fonction de leur contenu.
Comment ABBYY contribue-t-il au traitement intelligent des documents ?
Le traitement intelligent des documents offre aux entreprises un grand nombre d’avantages financiers — s’il est mis en place de façon stratégique, en tant que contributeur essentiel à l’expérience client, et si les processus sont construits en fonction de lui. En commençant par exploiter au mieux l'exploration des processus (Process Mining) et en posant des bases solides pour sa mise en œuvre, les entreprises peuvent engranger tous les bénéfices de l’IDP, y compris des coûts réduits, une amélioration de l’efficacité, de la conformité réglementaire, ainsi que de l’expérience client et salarié.
Les technologies d’ABBYY, leaders sur le marché, fournies avec une approche low-code / no-code, alimentent ABBYY Vantage, la nouvelle plateforme de traitement intelligent des documents pour la force de travail numérique.
Au fil des ans, nous, chez ABBYY, avons appris que les clients aimeraient vraiment profiter de compétences déjà formées, prêtes à l’emploi et immédiatement exploitables. C’est pourquoi nous avons lancé ABBYY Marketplace, communauté numérique en ligne au sein de laquelle les clients peuvent télécharger des compétences et d’autres ressources technologiques qui ajoutent encore plus de valeur à la plateforme ABBYY de traitement intelligent des documents.
Avec Vantage, il est possible de créer et former vos propres modèles de compétences de document, sans avoir besoin d’être un expert en OCR, ni en machine learning. L’intervention humaine au moment de la vérification alimente l’apprentissage en ligne, ce qui permet d’améliorer vos modèles. Or, la clé de l’adaptabilité de cette solution et de l’application de cette technologie à de nombreux secteurs d’activité différents est cette capacité à s’adapter à différents types et variations de documents.
Prêts à accélérer votre transformation numérique et à changer la façon dont vous automatisez le traitement de vos documents ? Contactez-nous dès aujourd’hui pour découvrir comment nous pouvons aider votre entreprise à mettre en œuvre une solution d’IDP fluide et adaptée à vos besoins.
Note éditoriale : le post de ce blog a été initialement publié le 8 décembre 2021, puis mis à jour le 28 août 2023, afin de clarifier la définition de ce qu’est le traitement intelligent des documents et de ses différences avec les modèles d’IA générative tels que ChatGPT. Quatre exemples récents d’utilisation de l’IDP montrent le parcours de transformation numérique de notre clientèle.
Maxime Vermeir
Senior Director of AI Strategy
Ayant plus de 10 ans d’expérience dans ces produits et cette technologie, Maxime Vermeir est un professionnel entrepreneurial animé par la volonté farouche de créer une expérience client exceptionnelle. En tant que directeur, il a dirigé des équipes internationales de consultants en innovation, ainsi que des initiatives transformationnelles pour le compte de grandes entreprises. Le partage de sa connaissance des nouvelles technologies et de la façon dont elles peuvent générer plus de valeur-client est un élément essentiel du panel d’expertise de Maxime. C’est un conseiller de confiance et un leader d’opinion dans ce domaine ; il suscite l’intérêt du marché pour les technologies ABBYY.