Back to ABBYY Blog
ABBYY FastML: A New Approach to Client-Side Machine Learning for Processing Large Document Flows
Stanislav Semenov
November 18, 2022
November 18, 2022

Our customers often need to handle large document flows, and many of such documents are very similar, but not the same. Since processing huge volumes of data has become increasingly challenging year after year, we developed an automated document processing technology solution capable of automating this task with high accuracy.
Move your intelligent document processing (IDP) strategy forward with ABBYY Vantage.
Say you receive tens of thousands of invoices from hundreds of business partners that you have to process. Previously, to automate classification and data extraction, you had to build a database of suppliers and manually create a flexible descriptor (input information about the linear relationship between fields relative to each other). It used to take a customer three to six months to implement this type of solution.
To simplify and accelerate this process, and facilitate our customers’ endeavor, we created a new clustering mechanism and developed FastML technology, and then combined their operation.
In our solution, clustering rules out the need to maintain a database of vendors because FastML works based on user learning: the technology splits a document flow into specific groups and trains a separate extraction model on each group. As a result, the new solution adapts more effectively to external differences in documents and operates several times faster.
But first thing's first.
First, let’s figure out the difference between classification and clustering in document processing.
Classification is required if a company constantly works with a limited number of vendors (e.g. ten) and is aware of the types of documents coming from them and what their differences are. In this case, the recognition model within the classifier is well trained and will work correctly.
Clustering is needed when a company works with ten thousand various partners, rather than ten. A customer has no accurate data on the content or structure of documents, nor is there any knowledge about the types and number of classes.
Clustering makes life a lot easier for the customer: there is no need to maintain a database of suppliers, constantly update it, and adjust settings—everything works automatically benefitting from the similarity function.
The similarity function is a function that quantifies the similarity between two objects. Values appear to be high for similar objects and either zero or negative for very dissimilar objects. In clustering tasks, the similarity function compares new documents with files from existing clusters, making it possible to break them into groups or create a new class.
For example, if a vendor changes the name of the company, but the document type remains the same, it will automatically continue to be processed by the same model from the existing cluster. If a vendor changes the document type alongside the name, the technology will automatically create a new cluster while making sure that no interruption in document processing will occur.
Let’s get back to the customer’s challenge of a large storage of unstructured documents and images, which are arranged into folders and subfolders. No information about their contents are available. The customer needs to cluster this array of files, to determine which file belongs to which partner.
This problem can be effectively addressed with clustering. Below is a sample clustering algorithm with example for this scenario.
It is a mechanism which, when applied to a pair of documents, returns a value in the range [0; 1] showing the degree of similarity of the documents. This is necessary to subsequently divide the documents into clusters. Incidentally, the function can be implemented in different ways: as a classifier (e.g., based on gradient boosting), as a neural network, or in some other way.
The similarity function can be expressed analytically or be embedded in the algorithm. Grid, SVD (singular value decomposition), Image, etc., as well as their combinations, can serve as attributes.
Two approaches can be identified: agglomerative (Figure 1) and divisive (Figure 2).
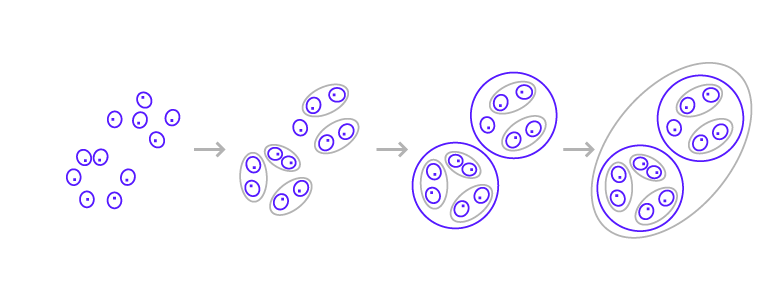 Figure 1
Figure 1In the merging approach, we look for two similar items and merge them into one. This task is performed repeatedly until the moment that all elements appear in a single common cluster. We need to pick certain thresholds that will indicate the ideal breakdown of documents. Once we ensure the partition that we need, we capture the required level of clustering, save it, and start using it.
Partitional clustering uses the same principle, but the other way round—from more to less.
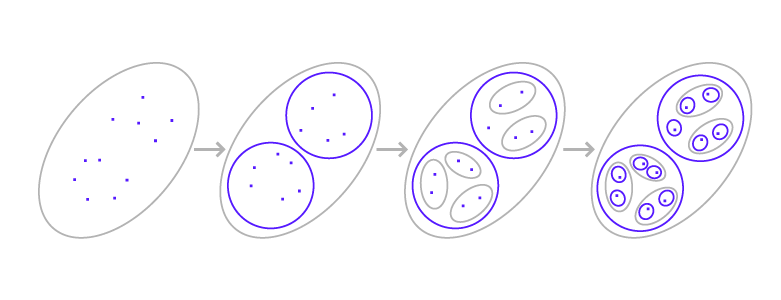 Figure 2
Figure 2For ABBYY's technology, we opted for the merging method, by starting to train clustering to determine whether a new document belongs to a specific group.
As an initial solution, we can take two random files from a group, compare them with a new document using the method from step 1, average out the estimate, make a decision based on a given threshold for inclusion in the group, and then change to the calculation of centroids for clusters and comparison with them.
Centroids are the centers of gravity in clusters. Each centroid is a vector, and its elements represent the mean values of the corresponding attributes calculated for all cluster entries.
Further on, second-level differential classifiers (e.g., SVM or Support Vector Machines) can be constructed for similar classes and retrained as cluster structure changes.
This will return the probabilities of a document getting into various groups (let’s call it the inverted index) and choose the most appropriate groups for further detailed testing of hypotheses for a document getting into this group by the method from step 2.
Let’s dive into this with a bit more detail.
In order to determine to which class (vendor) a new document belongs, we need to search and find the closest and most similar cluster. To this end, we apply the inverted index mechanism (Figure 3).
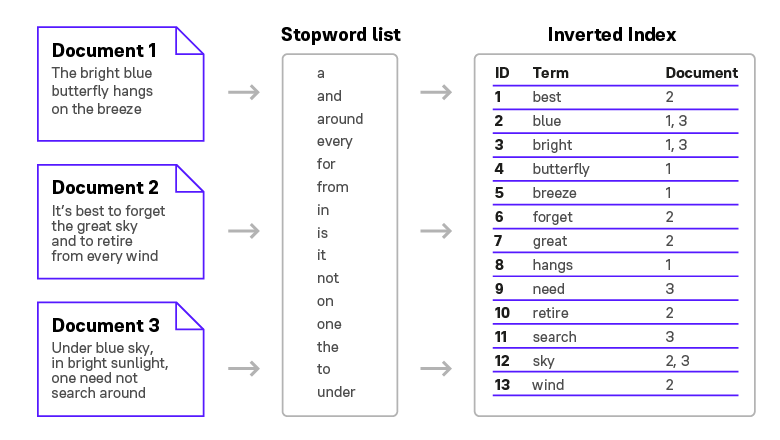 Figure 3
Figure 3Inverted index is a data structure, in which for each word encountered in a document collection, all documents of the collection in which it occurs, are given in a corresponding list. It is used for search in texts. The index may contain only a list of documents for each word or additionally include the position of the word in each document.
This requires that all the words from the document should be extracted, and then a number should be assigned to each word in the dictionary. The mechanism searches for other documents, in which the same words occur. If most of the words are found in many documents from one cluster, we assume that the new file belongs to the same cluster.
The index for the ranking function is rebuilt so that it can also factor in this new group.
In practice we find this out when a user makes a correction, and in our example, this occured from the labeling by vendor.
If we follow this algorithm, the result will be that each group will only contain representatives of a single vendor. Furthermore, several groups can be created for a single vendor, for example, depending on the attributes of a document.
Errors can be minimized by selecting the best parameter values and thresholds. Groups can be minimized (where necessary) by merging them, for example, if several groups are generated for one vendor.
Therefore, if the similarity function and the set of attributes are selected properly, it is possible to organize documents into a very large number of groups (tens of thousands). A regular classifier will not cope with this task, but the clustering mechanism can.
We have combined the FastML technology with the clustering mechanism. It replaces the training of flexible descriptors, works faster than the previous method, adapts more effectively to a variety of document structures, and offers several other advantages, which we’ll describe below.
It is possible to extract extract data from documents using a visual word dictionary, to which we also applied the clustering mechanism. We created this mechanism as a prototype to work with documents which have no anchor text, i.e. no field names (such as “Name”, “Date”, “Total”).
FastML technology brings together the visual and textual methods, thus enabling us to achieve even greater accuracy of data extraction in documents of any type.
FastML is a fundamentally new client-side learning technology that works in gear with a high-quality document clustering mechanism: clustering breaks down new documents into groups based on their similarity, and for its part, FastML learns well from similar files, thereby ensuring accurate search and data retrieval required by the customer.
The operation of FastML can be divided into two stages: training a model on a specific cluster and running that model on documents in that cluster. Notably, each cluster has its own trained model.
Stage 1: The first thing for a user to do at the training stage is to independently label the necessary fields in a document (all of them or select some)—a user needs to pick three to five documents of each type from the total set of files. For each labeled field, possible stable patterns of mutual arrangement with other fields (a heat map) are detected, along with various key (frequency) words. The mutual arrangement of fields can be determined by their absolute or relative positions, or by the area of permitted distribution of certain fields or keywords.
Among other things, this technology bundle allows addressing the label validation challenge. All of the discovered fields are divided into three groups:
Once a user is through with training, the model can be applied to the same cluster to detect fields in new documents.
Stage 2: The application of this new model can be divided into three steps.
The original idea underlying the training of flexible descriptors and FastML is similar—both technologies learn from uploaded documents. However, the concept (and result) of their operation is different. The table below clearly shows how.
|
Document processing stages |
Flexible descriptors + database |
FastML + clustering |
|---|---|---|
|
Document upload |
The quality of technology operation depends on the volume of a customer’s documents used to learn Weakness: The model works better on a small number of documents |
Works equally well on any volume of uploaded documents |
|
Document grouping
|
Arranged by vendor using a database (DB) Weakness: DB collection takes a long time |
Arranged with the clustering technology (no need to maintain a database) |
|
Model training process on 1–2 labeled documents |
The model learns the geometric relations of the elements relative to each other Weakness: Limitation apply to the complexity of the geometric representation of the mutual arrangement of fields |
The model learns from the field finding probability distribution. No conflicts are reported for this approach
|
|
Initiating a trained model to process new documents in a particular cluster (vendor) |
The model finds keywords and checks their geometric relationships Weakness: Takes a long time, is not always accurate, there is a risk of errors with a large number of heterogeneous documents in training
|
After finding keywords and other reference elements, the model builds a probabilistic distribution of a field, then determines areas of possible locations. Since the search area is small, this process is much faster compared with flexible descriptors. Next, the algorithm, based on the defined rules (and format), checks whether the discovered words are suitable |
As shown in the comparison table, the new FastML technology in combination with clustering (Figure 4) works faster than flexible descriptors, requires no mandatory collection and expansion of vendor databases, and improves the quality of retrieved data.
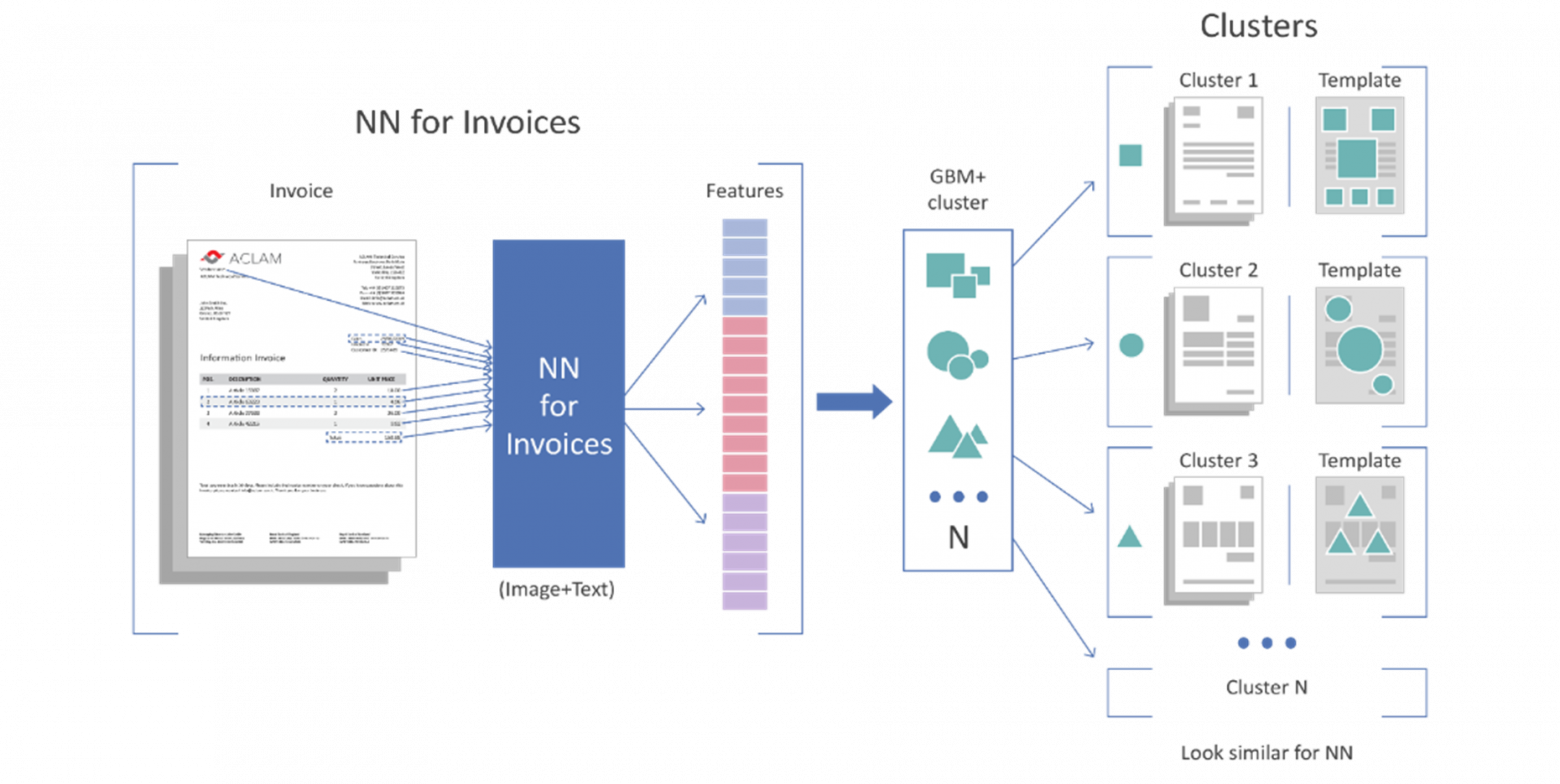 Figure 4
Figure 4We at ABBYY have created a fundamentally new solution for processing large arrays of documents. FastML combined with clustering is a state-of-the-art technology that is markedly superior in speed and quality to all previous developments in this area. Furthermore, it can be built into low-code/no-code systems, which are currently very popular solutions with companies.
Incidentally, FastML already works within our new low-code/no-code intelligent document processing platform ABBYY Vantage. Vantage empowers our customers to train the solution to detect and identify the necessary types of documents in a real-time basis. We’ll tell you more about this in one of our upcoming Tech Talk posts.
FastML is another step to client-side learning. We are currently working on the possibility of consistent training of both FastML and neural networks. Stay tuned—you won’t want to miss them!

Stanislav Semenov
Head of Document Processing
Stanislav is Head of Document Processing at ABBYY and leads a team of over 20 engineers developing AI-based data extraction technologies. He is the author of 30+ patents in the field of document processing.
