Künstliche Intelligenz von ABBYY
Purpose-Built-AI Center
Ihre zentrale Anlaufstelle um Einblicke in die hochmodernen KI-Tools von ABBYY zu erhalten – Bereitstellung präziser Daten für die Automatisierung von Geschäftsprozessen.

Im Mittelpunkt der Lösungen von ABBYY steht eine Kombination von Technologien, die eine erstklassige intelligente Dokumentenverarbeitung (IDP) ermöglichen.
Innovative KI ist in der ABBYY IDP-Plattform in alle Schritte der intelligenten Dokumentenverarbeitung integriert, von der Bildverbesserung über die Objekterkennung, OCR/ICR, die Klassifizierung und die Extraktion aus halbstrukturierten Dokumenten bis hin zur Extraktion aus unstrukturierten Dokumenten.
Mit der richtigen Kombination von Technologien und Techniken können die IDP-Lösungen von ABBYY jede Art von Dokument verarbeiten – jedes Format, jede Sprache, jede Struktur. Alle unsere spezialisierten Techniken wurden für bestmögliche Schlussfolgerungen bei einer möglichst geringen Menge an benötigten Ressourcen optimiert, um Kosten zu optimieren und den größtmöglichen ROI für unsere Kunden zu erzielen.
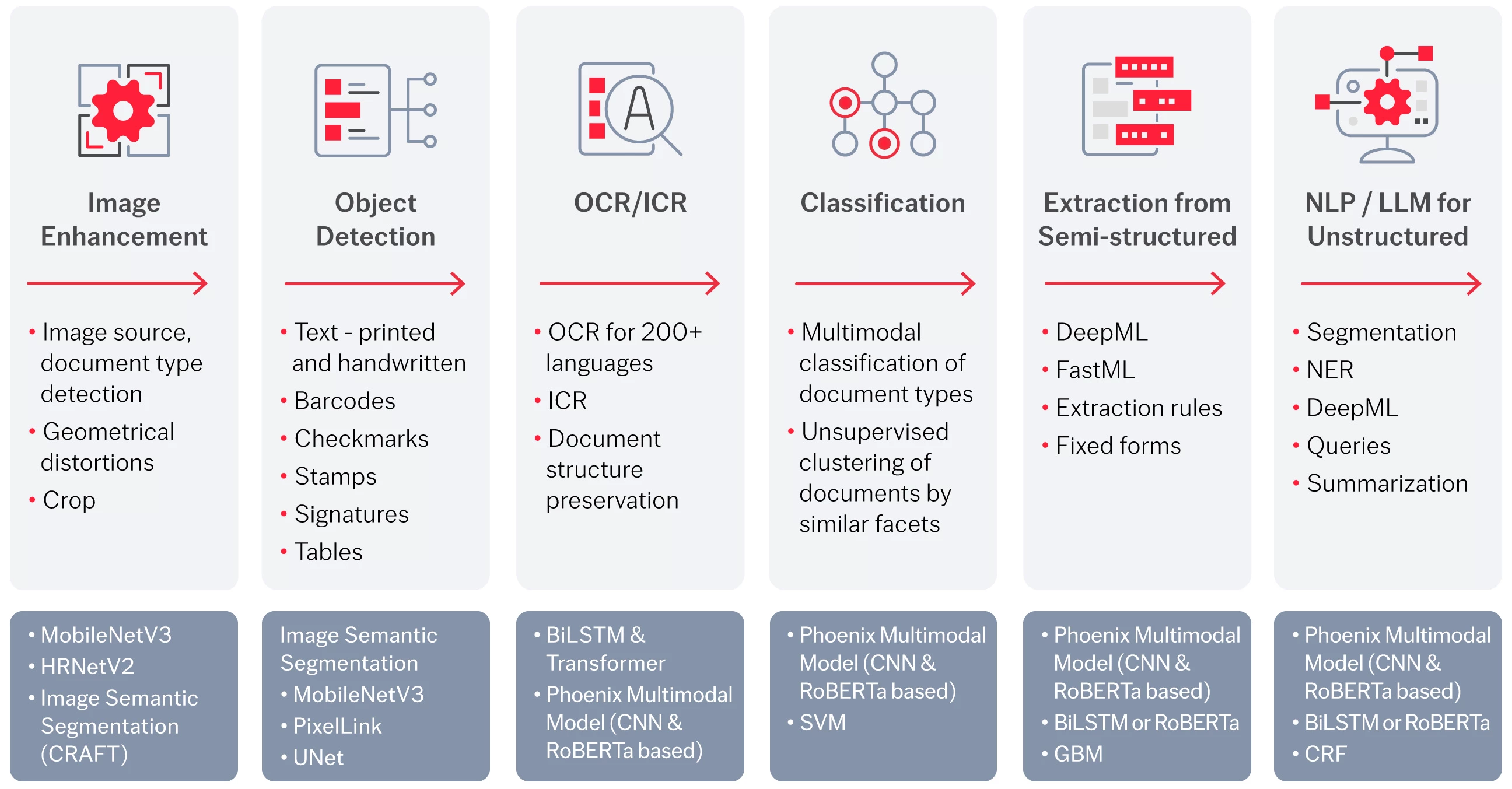
Hochmoderne KI-Tools als Grundlage für maßgeschneiderte Lösungen von ABBYY
Eine Kombination aus hochgradig optimierten KI-Modellen und -Algorithmen für die jeweilige Aufgabe.
Phoenix 1.0
Phoenix 1.0 ist ein hochmodernes multimodales Modell, das erweiterte Bild- und Textanalyse kombiniert, indem es Convolutional Neural Networks (CNNs) zur visuellen Datenverarbeitung in das auf Textverständnis trainierte RoBERTa-Sprachmodell integriert. Phoenix verfügt über eine innovative KI-gesteuerte Pipeline, die Zero-Shot-Extraktionsfunktionen für Schlüssel-/Wertpaare bietet und damit eine Automatisierung des oft mühsamen Dokumentmodelltrainings ermöglicht. Im Gegensatz zu allgemeiner angelegten Sprachmodellen, die ein breites Spektrum von Sprachverständnisaufgaben abdecken, stellt Phoenix ein robusteres Framework für die Dokumentenverarbeitung zur Verfügung, insbesondere beim Umgang mit multimodalen Daten. Es bietet erweiterte Funktionen zur Merkmalsextraktion, Effizienz bei der Verarbeitung von Arbeitsabläufen und ein tieferes Kontextverständnis, das mit umfassenden Sprachmodellen allein wahrscheinlich nicht vollständig erreicht wird. Diese Spezialisierung macht es zur idealen Wahl für Anwendungsfälle, die stark auf Informationen angewiesen sind, die über Dokumente übertragen werden. Zugleich gewährleistet sie eine präzise Datenverarbeitung mit schnellen Durchlaufzeiten.
Phoenix wurde entwickelt, um die Effizienz und Effektivität von Dokumentenverarbeitungsaufgaben zu steigern. Durch Nutzung der Stärken von Convolutional Neural Networks für die Bildanalyse zusammen mit dem erweiterten Sprachverständnis von RoBERTa ermöglicht diese Integration ein differenziertes Verständnis komplexer Dokumente, die sowohl Text- als auch visuelle Elemente enthalten. Mithilfe des fokussierten Ansatzes können Unternehmen eine höhere Genauigkeit bei der Extraktion und Analyse von Informationen erreichen als bei der Verwendung von Allzweckmodellen. Darüber hinaus minimiert das Design den Ressourcenverbrauch, indem der Verarbeitungsablauf, rationalisiert wird, was die Verarbeitungsgeschwindigkeit steigert und die Betriebskosten senkt. Dadurch können Unternehmen Dokumente effektiver verarbeiten, einen erheblichen Mehrwert erzielen und ihre Gesamtproduktivität steigern.
Machine Learning
Unsere intelligente Dokumentenverarbeitung nutzt einen Mix von Technologien, um eine unvergleichliche Leistung zu erzielen. Eine Kombination aus Deep Machine Learning und schnellem maschinellem Lernen maximiert die Straight-Through-Processing-Rate (STP). Mit unseren dokumentenspezifischen KI-Modellen, die durch Deep Machine Learning trainiert wurden, können unsere Kunden eine Genauigkeit von bis zu 90 Prozent erreichen. Mit der Einbeziehung von schnellem maschinellem Lernen klettert die Genauigkeit jedoch auf über 95 Prozent. Die Technologie merkt sich die Ausreißer, die das Deep Machine Learning nicht abdecken konnte, und es funktioniert schnell, mit nur wenigen Variationen der betreffenden Dokumente. Und mit den Daten, die wir bei diesem Prozess sammeln, verbessert sich unser Deep Learning kontinuierlich und erzielt mit der Zeit eine immer höhere Genauigkeit.
Mit Deep Learning können wir KI-Modelle speziell für Aufgaben der Dokumentenverarbeitung vortrainieren. Im Gegensatz zu Allzweck-LLMs oder Gen AI, die für ein breites Spektrum von Aufgaben konzipiert sind, zeichnen sich unsere Deep-Learning-Modelle durch ihre Spezialisierung aus und liefern zuverlässigere und genauere Ergebnisse.
- Deep Machine Learning (ML) verwendet CNNs (Convolutional Neural Networks), RNNs (Recurring Neural Networks) und NLP (Natural Language Processing), um Informationen aus halbstrukturierten Dokumenten zu extrahieren. Es generalisiert über verschiedene Dokumentenformate hinweg und verarbeitet unbekannte Layouts effektiv, ohne auf Vorlagen angewiesen zu sein. Obwohl für eine genaue Feldextraktion eine beträchtliche Menge an gekennzeichneten Daten – zwischen 500 und 10.000 Dokumenten – erforderlich ist, gewährleistet der erweiterte Trainingsprozess eine hohe Präzision und macht es zu einem leistungsstarken Werkzeug für die Interpretation komplexer Daten.
- Fast Machine Learning (ML) konzentriert sich auf textuelle und visuelle Muster und arbeitet effizient mit nur einem oder zwei Dokumenten pro Satz. Es verwendet eine Clustering-Technologie, die ähnlich aussehende Dokumentenlayouts zusammenfasst und intern ein Feldextraktionsmodell für jedes Cluster trainiert. Im Gegensatz zu Deep ML konzentriert sich das System bei diesem Ansatz auf Dokumentvariationen, die es bereits „gesehen“ hat, anstatt die Muster zu generalisieren. Sein klarer Vorteil ist, dass es den Lernprozess beschleunigt, weniger CPU-Leistung benötigt und kürzere Verarbeitungszeiten ermöglicht.
OCR & ICR – optische Zeichenerkennung und Handschrifterkennung
ABBYY ist ein Pionier auf dem Gebiet der optischen Zeichenerkennung und forscht und entwickelt in diesem Bereich seit 1993, als unser erstes Omnifont-OCR-System ABBYY FineReader auf den Markt kam. Im Laufe der Jahre hat sich die Technologie von der Erkennung einzelner Zeichen, der Identifizierung von Wörtern und der Reproduktion der Seitenstruktur hin zur Anwendung der adaptiven Dokumentenerkennungstechnologie (ADRT®) entwickelt, die Dokumente in ihrer Gesamtheit versteht, einschließlich Layout, mehrseitiger Struktur und Elementen wie Kopf- und Fußzeile sowie Inhaltsverzeichnis.
Mit dem Fortschritt auf dem Gebiet der künstlichen Intelligenz hat ABBYY in den letzten Jahren seinen End-to-End-Ansatz für OCR und ICR entwickelt und gefestigt. Bei diesem Ansatz kommen dieselben Technologien zum Einsatz, die auch die Grundlage für generative KI-Tools bilden – Convolutional Neural Networks, Transformatoren und Sprachmodelle.
Das Convolutional Neural Network zerlegt ein Bild von handgeschriebenem oder gedrucktem Text auf einem Dokument in seine Bits und Bytes und versucht zu verstehen, was es eigentlich ist. Der gesamte Input des CNN geht dann in einen Transformator, um ein mögliches Ergebnis eines Wortes zu liefern. Dann ziehen wir unser eigenes LM heran, das auf Milliarden von Parametern trainiert ist und die spezielle Funktion hat, den Kontext aller verschiedenen Wörter in einer Gruppe zu berücksichtigen und diese Informationen bestmöglich zu nutzen, um zu einer Schlussfolgerung zu gelangen. Diese Technik verbessert die Leistung und Genauigkeit unserer OCR- und ICR-Funktionen insgesamt drastisch und wird in Kombination mit unserem statistischen Ansatz eingesetzt. Unsere KI entscheidet automatisch, welcher Ansatz für Ihre Dokumente am besten geeignet ist, um die Konsistenz, Genauigkeit und Geschwindigkeit zu optimieren und bessere Verarbeitungsraten zu erzielen.
Computer Vision
ABBYY setzt fortschrittliche Computer-Vision-Technologie als Schlüsselkomponente seiner intelligenten Dokumentenverarbeitungslösungen ein, um die Automatisierung und Datenextraktion aus komplexen Dokumenten zu verbessern. Durch die Integration von neuronalen Netzen, einschließlich Convolutional Neural Networks (CNNs) und Transformatoren, verarbeitet ABBYY visuelle Inhalte wie Text, Bilder und sogar handschriftliche Dokumente. Die CNNs zerlegen visuelle Elemente in Dokumenten und identifizieren Muster in gedrucktem oder handgeschriebenem Text, während Transformatoren den Kontext analysieren, um die Genauigkeit der Wort- und Zeichenerkennung zu verbessern. Diese Technologie ermöglicht ABBYY die genaue Interpretation und Klassifizierung einer breiten Palette von Dokumenttypen, von strukturierten Formularen bis hin zu unstrukturierten, textlastigen Inhalten.
Darüber hinaus enthalten die Lösungen von ABBYY Techniken zur Objekterkennung, um Merkmale wie Barcodes, Unterschriften und Stempel zu identifizieren, die für Anwendungen in Branchen wie Versicherung und Logistik unerlässlich sind. Durch die Kombination von Computer Vision mit Sprachmodellen und anderen KI-Technologien verbessert ABBYY die Möglichkeiten der Dokumentenverarbeitung und ermöglicht es Unternehmen, Arbeitsabläufe effektiver zu automatisieren, manuelle Fehler zu reduzieren und die Verarbeitungsraten zu verbessern.
Natural Language Processing
Durch die Einbettung von Natural Language Processing (NLP) in seine intelligenten Dokumentenverarbeitungslösungen bietet ABBYY Unternehmen, die ihre Dokumentenmanagementprozesse optimieren wollen, entscheidende Vorteile. Dank fortschrittlicher NLP-Techniken wie Named Entity Recognition (NER), Deep Machine Learning (DeepML) und Zusammenfassung zeichnet sich die Vantage-Plattform von ABBYY durch die effiziente Extraktion strukturierter Daten aus strukturierten und unstrukturierten Dokumenten aus. Durch die Integration von Deep-Learning-Funktionen bietet die Plattform ein anpassbares NLP-System, das sich auf individuelle Geschäftsanforderungen abstimmen lässt. Sowohl Entwickler als auch Geschäftsanwender können diese Systeme so trainieren, dass sie kundenspezifische benannte Entitäten erkennen, wodurch eine maßgeschneiderte Lösung gewährleistet wird und gleichzeitig Transparenz und Kontrolle über die verwendeten Modelle erhalten bleiben. Diese Eigenschaft ermöglicht schnellere und präzisere Geschäftsabläufe, z. B. durch eine beschleunigte Kreditbearbeitung und ein rationalisiertes Vertragsmanagement.
Die Anwendung der NLP-Funktionen von ABBYY bringt erhebliche Vorteile für Unternehmen mit sich. Dazu gehören eine gesteigerte betriebliche Effizienz durch die Automatisierung von Routineaufgaben in der Dokumentenverarbeitung, deutliche Verbesserungen bei der Genauigkeit und Zuverlässigkeit der Datenextraktion sowie eine höhere Verarbeitungsgeschwindigkeit, die schnellere Entscheidungsprozesse ermöglicht. Darüber hinaus helfen die Lösungen von ABBYY bei der Einhaltung von Vorschriften und beim Datenschutzmanagement, indem sie sensible Informationen in Übereinstimmung mit den gesetzlichen Standards präzise identifizieren. Branchen wie das Bank- und Finanzwesen, das Rechtswesen und das Gesundheitswesen sind besonders geeignete Zielgruppen für diese fortschrittlichen Techniken, darunter Segmentierung, Abfrageerstellung und Zusammenfassung. Diese Tools ermöglichen es Unternehmen, Rohdaten in verwertbare Erkenntnisse umzuwandeln und so den Service für Kunden zu verbessern und die betriebliche Effizienz in allen Bereichen zu steigern.
NeoML
NeoML ist das umfassende Open-Source-Framework von ABBYY für maschinelles Lernen, das sowohl für Deep Learning als auch für herkömmliche maschinelle Lernaufgaben entwickelt wurde. Dieses vielseitige Tool unterstützt über 100 Arten von neuronalen Netzschichten und mehr als 20 traditionelle Algorithmen des maschinellen Lernens, wodurch es für eine Vielzahl von Anwendungen wie Computer Vision und Natural Language Processing geeignet ist. Die Kompatibilität von NeoML mit plattformübergreifenden Umgebungen, einschließlich Windows, Linux, macOS, iOS und Android, gewährleistet eine nahtlose Integration in bestehende Unternehmensinfrastrukturen. Darüber hinaus unterstützt NeoML das Open Neural Network Exchange (ONNX)-Format, das die Interoperabilität mit anderen Werkzeugen für maschinelles Lernen ermöglicht, was seine Anwendbarkeit in verschiedenen Programmierumgebungen durch Sprachen wie C++, Java und Objective C weiter erhöht.
Für Unternehmen bietet NeoML eine robuste, skalierbare und kosteneffiziente Lösung für den Einsatz von Machine-Learning-Modellen in verschiedenen Geschäftsfunktionen. Dank seiner Open-Source-Eigenschaften, die durch eine Apache 2.0-Lizenz abgedeckt sind, können Unternehmen NeoML ohne hohe Kosten an ihre spezifischen Bedürfnisse anpassen und so die Effizienz der Ressourcenzuweisung maximieren. Dank der umfassenden Unterstützung durch die Community profitiert NeoML von kontinuierlichen Verbesserungen und Aktualisierungen, die sicherstellen, dass Unternehmen Zugang zu modernsten Machine-Learning-Kapazitäten haben. Die hohe Leistung des Frameworks, die sowohl durch CPU- als auch GPU-Unterstützung ermöglicht wird, garantiert eine schnelle Datenverarbeitung und zeitnahe Ergebnisse. Das macht es zu einer idealen Wahl für Unternehmen, die maschinelles Lernen nutzen möchten, um Innovationen voranzutreiben und die betriebliche Effizienz zu optimieren.

Carlsberg
U.S. FDA
Emerson
Carlsberg beschleunigt die Markteinführung von Getränken
Beschleunigte
Lieferungen und höhere Kundenzufriedenheit
>140
Stunden pro Monat eingespart
92%
kontaktlose Auftragsabwicklung

Mithilfe von intelligenter Dokumentenverarbeitung hat Carlsberg seine Bestell- und Lieferprozesse digitalisiert.
U.S. FDA nutzt IDP zum Schutz der öffentlichen Gesundheit
35 %
Straight-Through-Rechnungsverarbeitung
40 %
schnellere Dokumentenverarbeitung
15 %
geringere Kosten und weniger Fehler

„ABBYY hat uns ins 21. Jahrhundert gebracht.“

Verbesserung der Customer Journey mit Process Intelligence
6 Mio. $ eingespart
durch verspätete Zahlungen pro Jahr
Optimierter
Schadenmanagement-Zyklus
Reduzierte
Verwaltungskosten

„ABBYY Process Intelligence hat uns geholfen, einen echten kulturellen Wandel zu vollziehen: Jetzt verlassen wir uns auf Daten und nehmen datengestützte Verbesserungen vor.“
- Simon Higgs, Director of Business Transformation
Wir lassen die Daten der weltweit größten Unternehmen für sie arbeiten
Über 10 000 Kunden
einschließlich vieler der Fortune 500 vertrauen ABBYY.
Mehr als 400 Patente
und Patentanmeldungen. Umfassende Technologieführerschaft in der intelligenten Prozessautomatisierung.
Mehr als 30 Jahre Erfahrung
mit intelligenten Automatisierungslösungen für Unternehmen auf der ganzen Welt.
Unsere Grundsätze einer vertrauenswürdigen KI
Verantwortungsvolle Datenwissenschaft
Wir haben uns zu einer strikten Produktentwicklung verpflichtet, die auf den verantwortungsbewussten Prinzipien der Datenwissenschaft basiert, d. h. Vertraulichkeit, Genauigkeit und Sicherheit, die in unser KI-gesteuertes Produktportfolio für intelligente Dokumentenverarbeitung und Process Intelligence eingebettet sind.
Vertraulichkeit der persönlichen Daten
Wir setzen auf „Privacy-by-Design“-Methoden, die es unseren Kunden ermöglichen, die Erfassung und Verarbeitung personenbezogener Daten zu kontrollieren und zu beschränken.
Qualitätssicherung und Produktqualität
Wir entwickeln ein KI-gesteuertes Produktportfolio, welches den Industriestandards für die Richtigkeit und Vollständigkeit von Informationen erfüllt.
Einhaltung des Branchenstandards für die Cyber-Sicherheit
Wir setzen Zero-Trust-Sicherheitsprinzipien ein, um die Risiken im Bereich der Cybersicherheit zu minimieren.


ABBYYs Ansatz zur ethischen KI
Purpose-Built-AI, die wirtschaftlichen Wert und Nutzen liefert
- Es ist uns ein Anliegen, die Eigenschaften unserer KI-Produkte transparent zu machen und Kundenfeedback zu ermöglichen.
- Im Rahmen des KI-Risikomanagements verfolgen wir einen strukturierten Ansatz zur Bewertung von Risiken während des gesamten Lebenszyklus unseres KI-gestützten Produktportfolios.
- Die Einhaltung der geltenden Vorschriften zum Datenschutz und zur künstlichen Intelligenz ist für uns selbstverständlich.
Erfahren Sie das Neueste über KI von ABBYY
ABBYY Marketplace beflügelt LLMs und RAG-Integrationen

ABBYY unterstützt die Entwicklung unabhängiger KI-Audit-Systeme

Das intelligente Unternehmen

ABBYY Marketplace beflügelt LLMs und RAG-Integrationen
ABBYY unterstützt die Entwicklung unabhängiger KI-Audit-Systeme
Das intelligente Unternehmen
ABBYY Marketplace beflügelt LLMs und RAG-Integrationen
ABBYY unterstützt die Entwicklung unabhängiger KI-Audit-Systeme
Das intelligente Unternehmen
Wissenswertes über ABBYY AI

Bericht
Bericht zum Stand der intelligenten Automatisierung: Einfluss der Wirtschaft auf die Akzeptanz von KI
Bericht
Bericht zum Stand der intelligenten Automatisierung: Einfluss der Wirtschaft auf die Akzeptanz von KI