人工知能(AI)は、いまやビジネス環境において競争力を維持するために欠かせない存在となっています。 多くのAI主導型ソリューションの中核をなすのが言語モデルです。言語モデルは、人間のように文章を理解し、生成できる強力なツールです。 これらの技術は、企業による文書やデータの扱い方と意思決定を行う方法そのものを大きく変えつつあります。
とはいえ、AIを本当に活用できるかどうかは、突き詰めれば「データの質」にかかっています。 正確でしっかりと定型化されたデータがなければ、どんなに高度な言語モデルであっても力を発揮できません。 本ガイドでは、大規模言語モデル(LLM)と小規模言語モデル(SLM)の違いをわかりやすく解説します。そして、質の高いデータと適切なモデルの選択こそが、ビジネスにおけるAIの可能性を最大限に引き出す鍵である理由をお伝えします。
ジャンプ
言語モデルとは何か?
言語モデルとは、人間の言葉を理解し、文章を作り、さらには先を予測するために開発されたAIの一種です。 基本的に、言語モデルは膨大なテキストを読み込むことで学習します。その過程で文法やパターン、言葉やフレーズの文脈を理解していくのです。 そして、その知識をもとに文章や段落を書いたり、質問に答えたり、言語を翻訳したりと、さまざまなことができるようになります。
小規模言語モデルとは?
小規模言語モデル(SLM)は、名前から想像できるように、よりコンパクトなスケールで動作する言語モデルです。 こうしたAIツールは、それぞれの目的に合わせて設計されており、特定のタスクに対して集中的かつ効率的に動作するよう作られています。
SLMは一般的に動作が速く、コストも抑えやすく、学習のプロセスも簡単です。そのため、特定の目的に絞ったタスクに適しています。 インテリジェント文書処理(IDP)のようなアプリケーションでは、SLMは目的に合わせて設計され、文書からのデータ抽出や文書分類、光学式文字認識(OCR)、自然言語処理(NLP)といった重要な機能を支えています。 SLMなら、多様な文書から正確に情報を取り出せるだけでなく、消費する計算リソースも少なくて済み、環境への影響もより小さく抑えられます。
大規模言語モデルとは何か?
大規模言語モデル(LLM)は、人間の言葉を高度に理解し生成できるAIで、さまざまな用途に活用できるのが特徴です。 微妙なニュアンスや複雑なパターンまで捉えられるのがLLMの強みであり、細かな違いを見抜き、ときに創造的で洞察に富んだ答えを導き出してくれます。
LLMは、実に幅広いタスクに対応できるよう設計されています。 たとえば1つのLLMで、多言語の請求書を作成したり、医療従事者向けの診療記録の作成をサポートしたりすることも可能です。 LLMは数十億ものパラメータで構築されているため、大きな計算資源を必要とします。しかし、その力を活かしてユニークなコンテンツを生み出したり、細やかな会話を再現したりと、多彩なことが可能になるのです。
小規模言語モデルのメリット
大きければいいというものではありません。 小規模言語モデル(SLM)には、特定のビジネスプロセスに最適な選択肢となるだけの多くのメリットがあります。 このようなコンパクトなAIツールを際立たせる5つの主なメリットを見ていきましょう。
高速パフォーマンス
特定のタスクを迅速に片付けたい場合は、SLMが最適な選択肢になるかもしれません。 SLMは、実際に担うタスクに直結した、より小規模で的を絞ったデータセットから学習します。 そのためSLMは学習させやすく、動作もスピーディーで、環境への負荷も抑えられます。
例えばSLMは、IDPの分野でよく活用されており、企業に届く文書からデータを素早く正確に識別・仕分け・抽出する役割を担っています。 SLMの活用例はほかにもあります。例えば、即時対応のカスタマーサービスを行うチャットボットや、会話を途切れさせないリアルタイム翻訳サービスなどが代表的です。
コストを抑えやすい
AIツールを導入するのに、必ずしも多額の投資が必要なわけではありません。 例えばSLMは、大規模モデルに比べて開発コストが低く、運用面でも手頃に利用できるのが特長です。 資金に限りがあるスタートアップでも、多大なコストをかけずにAIの力を活用するチャンスがあります。
特定の組織にカスタマイズした活用法
企業ごとに必要とするものは異なります。SLMなら、法的書類から医療の予約管理まで、そのニーズに合わせて目的別に設計することができます。 自社の専門情報を学ばせれば、その分野に強い「頼れる専門家」として活躍してくれます。 すべてを一つの形に当てはめる必要はありません。
正確性
ピンポイントで確実な結果が求められるとき、SLMはしばしば最適な選択肢となります。 SLMは特定のタスクに絞って学習しているため、大規模モデルよりも精度が高くなる場合があり、しかも処理時間はごくわずかで済みます。 SLMは、微妙なニュアンスを含む質問の文脈を理解し、その専門分野に即したユニークで意味のある回答を生み出すことができます。 実際、汎用的な大規模モデルではなく、自社のニーズに合ったSLMを選ぶ企業が増えてきています。
アップデートが容易
ビジネスは常に時代の変化に適応しなければなりません。そのため、AIツールもその変化に柔軟に対応できる必要があります。 SLMは開発やアップデートがしやすいため、手をかけずに最新の情報や業界動向に合わせて常にアップデートしていくことができます。 企業が進化を続けても、モデルは常に最新の状態に保たれ、価値ある情報を提供し続けます。
大規模言語モデルのメリット
大規模言語モデル(LLM)は膨大なデータで学習しているため、創造的な文章を生み出したり、複雑な質問に答えたり、文脈やニュアンスを理解したりすることができます。 ただしLLMは、“もっともらしいけれど誤った情報”や“意味の通らない内容”を生成してしまう、いわゆる「ハルシネーション(幻覚)」を起こすこともあります。 こうした制約はあるものの、LLMの持つ可能性は大きく、企業にとっても個人にとっても非常に強力なツールとなり得ます。
膨大なナレッジベース
LLMは膨大な情報を学習しているため、言語だけでなく世界についても幅広い理解を備えています。 これらのモデルは、幅広い質問に答えたり、多様な情報を要約したり、さらには驚くほど正確にクリエイティブなコンテンツを生み出したりすることができます。
適応性と柔軟性
LLMは驚くほど多才です。 ChatGPTやGeminiといった汎用型のオープンソースLLMが広く知られており、こうしたモデルも特定のビジネス用途に合わせて調整したり、事前学習させたりすることが可能です。 例えばLLMは、書類から必要な情報を引き出すように調整したり、変化する政府規制への対応を企業がスムーズに行えるよう支援したりすることができます。 企業はLLMをカスタマイズすることで、業界特有のさまざまな業務にも対応させることができます。
多言語対応
多くのLLMは複数の言語を理解し、生成することができます。 これは、複数の国に拠点を持つ企業や、海外の取引先や顧客とやり取りする企業にとって特に役立つ機能です。 コミュニケーションやコラボレーションも、国境を越えてこれまで以上にスムーズに行えるようになります。
知識の統合
LLMは大量の情報を扱い、それを整理・理解するのが得意です。深い理解や詳細な分析が求められるタスクに役立ちます。 例えばLLMなら、数千件に及ぶ法的文書をチェックして要点をまとめられるため、弁護士はすべてを一字一句読むことなく全体像を把握できます。 複雑な情報を収集し、関連付けるこの能力によって、LLMは綿密なリサーチにも有用な存在となります。
創造性の向上
LLMは多様で膨大な言語データで学習しているため、業界特有の専門用語やコミュニケーションスタイルも含め、プロフェッショナルなコンテンツを生成するのに非常に優れています。 ただし、特にビジネスの現場でLLMを活用する際には、良質なデータをもとにすることが良い結果を得るための鍵となります。 適切なデータにアクセスし、さらに検索拡張生成(RAG)によって外部のナレッジソースとつなげることで、LLMは説得力のあるマーケティングコピーの作成洞察に富んだレポートの生成に加え、さらにはパーソナライズされたメールの返信まで行うことができます。その際もブランドの一貫したトーンを保つことが可能です。 高度な言語処理能力によって、LLMは説得力があり情報性の高いアウトプットを生み出せるため、ビジネスコミュニケーションやコンテンツ制作において非常に価値のあるツールとなります。
小規模言語モデル vs 大規模言語モデル: その違いは?
規模と複雑さ
大規模言語モデル(LLM)は、小規模言語モデル(SLM)よりもはるかに大量の知識を保持しています。 その理由は、LLMが数億規模に及ぶ膨大なパラメータを備えているからです。その結果、高度な性能を発揮し、幅広いタスクに対応できるのです。
しかしLLMは処理に時間やリソースを多く必要とし、小規模モデルと比べて情報処理に最大で50倍もの時間がかかる場合があります。 一方、SLMはより効率的に設計されており、そのパラメータ数は100万から1000万程度に抑えられています。 この設計により、SLMは学習も利用もより速く、効率的に行うことができます。
コストとリソースの要件
SLMが燃費の良いコンパクトカーだとすれば、LLMは大型トラックのような存在です。 LLMははるかに多くの計算能力とメモリを必要とするため、運用コストが高くつく場合があります。 また、LLMは膨大なエネルギーを消費するため、環境への影響も大きくなりがちです。 一方、SLMは軽量でエネルギー消費も少なく、多くの場合、標準的なハードウェア上で動作させることができます。
能力
LLMは非常に幅広いタスクに対応でき、正確で自然な結果を出すことに優れています。 対照的に、SLMは特定の用途に特化しているため、限られたリソースで動作しつつ、コストを抑えながら高いパフォーマンスを発揮できます。
例えば、支払い処理向けに特化した小規模言語モデルなら、経理チームに本当に必要な情報だけを正確に抽出し、不要なデータはすべてスキップできます。 こうした特化型のアプローチは、処理を高速化するだけでなく、より大規模なモデルに匹敵する精度を発揮することもあり、しかもリソース負担も軽く済みます。
LLMとSLMの例
小規模言語モデルの例
SLMは、その特化した専門性と効率性によって、さまざまな業界を変革しつつあります。 例えば、インテリジェント文書処理(IDP)向けに調整されたSLMなら、文書処理における光学式文字認識(OCR)の精度を高めることができます。 これにより、ワークフローの処理時間が短縮されるだけでなく、手作業と比べてエラーも減らすことができます。
大規模言語モデルの例
ChatGPTのような人気AIツールを支えているのがLLMです。広告キャンペーンのアイデア出しから書類の翻訳まで、幅広いタスクをこなすことができます。 とはいえLLMも、特定のタスクに直結する数十億ものパラメータで追加学習させることで、より精緻に調整することが可能です。 例えば医療分野では、LLMを膨大な医学文献や患者記録のデータセットで追加学習させることで、複雑な医療に関する質問に答えられる専門家のような存在に育てることができます。
RAG LLMおよびSLM
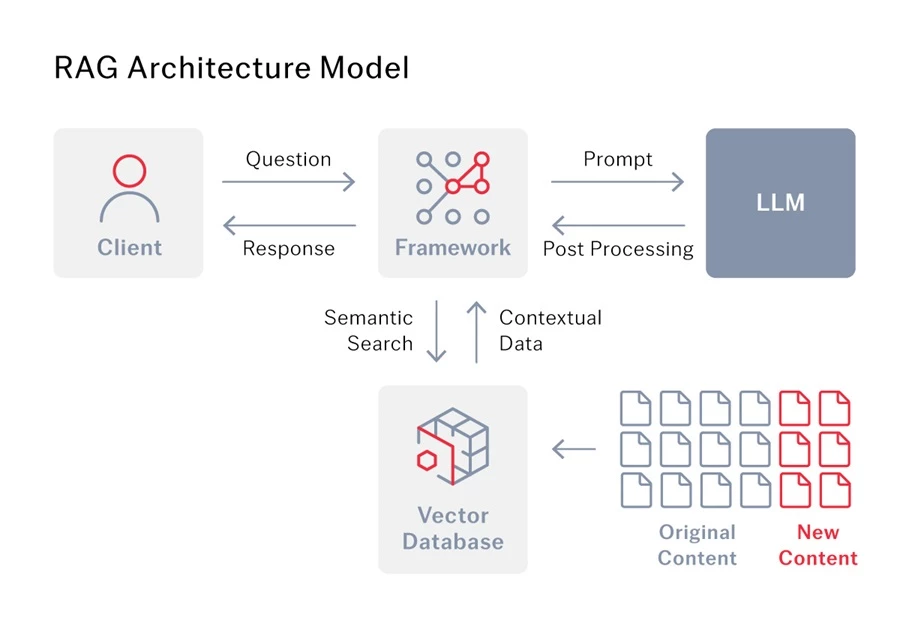
検索拡張生成(RAG)とは?
検索拡張生成(RAG)は、言語モデルがより的確な答えを返せるようにする高度なAI手法です。 通常、言語モデルは学習時に取り込んだ情報だけに依存して動作します。 しかしRAGを使えば、モデルは別のナレッジベースやデータベースにもアクセスでき、その追加情報を活用してより正確な回答を生成できるようになります。
LLM向けのRAG
LLMは文章生成には優れていますが、その知識は時間が経つと古くなってしまうことがあります。 検索拡張生成(RAG)はこの問題を解決するものです。LLMをインターネットや専門データベースなど外部の情報源とつなぐことで、常に最新かつ関連性の高い情報にアクセスし、質問に答えられるようにするのです。
ただし、RAGは精度を向上させるだけではありません。 RAGは取得した情報を質問の文脈と組み合わせることで、LLMがユーザーそれぞれのニーズをより正確に理解できるようにします。 これにより、よりニュアンスに富んだ適切な回答が得られ、「ハルシネーション」が生じる可能性も減ります。 ここで重要なのは高品質なデータです。LLMが本当に洞察に富んだ答えを生み出すには、より深い文脈を与えてくれるデータが欠かせません。
インテリジェント文書処理(IDP)を例にとってみましょう。 企業がIDPとLLMを組み合わせて活用する場合、RAGはその両者をつなぐ「橋渡し」の役割を果たします。 基本的にRAGは、LLMがIDPによって抽出されたデータにアクセスして活用できるようにし、より正確な成果を生み出すために必要な情報を与える役割を果たします。
ニーズに合った言語モデルの選択
どの言語モデルが最適かは、何に使いたいかによって決まります。 LLMは膨大な文脈理解が必要なタスクに最適ですが、SLMは特定のタスクに集中して取り組むのに向いており、しばしば大規模なプラットフォームに組み込まれて専門的な機能を効率よく担っています。
実際、あなたが普段使っているツールの中にも、すでにSLMが組み込まれているかもしれません。 例えばABBYYのIDPプラットフォームでは、OCRなどのタスクにSLMを活用し、さらに機械学習や画像セマンティックセグメンテーションといった他のAI技術も組み合わせています。 これらのツールが連携することでプロセスの自動化と精度向上が実現し、ワークフローをより効率的にすることができます。
LLMとSLMの組み合わせ
受賞歴のあるインテリジェント・オートメーションサービス企業のAshlingは、顧客のためにリース関連文書から350項目以上を抽出するソリューションを必要としていました。文書は品質・種類・形式・言語がバラバラで届くためです。 この課題を解決するため、Ashlingは5つの異なるアプローチで複数の技術を組み合わせて検証し、その中で圧倒的に優れた成果をもたらした組み合わせにたどり着きました。 その答えは、ABBYY VantageやGPT-4 TurboといったLLMとSLMに、Blue PrismのRPA(ロボティック・プロセス・オートメーション)を組み合わせる方法でした。
GPT-4とABBYY Vantageを組み合わせることで統合的なユーザー体験が実現し、フィールド単位での学習を行う前から結果を出すことができました。 このアプローチでは、分類とセグメンテーションにIDPを活用し、フィールド抽出には生成AI(GenAI)を用いています。 生成AI、IDP、RPAを統合してデータ抽出と入力を自動化した結果、82%の精度を達成しました。 設定した信頼度のしきい値を下回った一部のフィールドについては、ABBYY Vantageのマニュアルレビュー機能を使い、人間のユーザーが機械抽出された値を修正できるようにしています。 機械学習モデルは人間が修正した値から学習し、時間とともに精度を高めていくため、手動でのレビュー作業は徐々に減っていきます。Ashlingのケーススタディ全文はこちらでご覧いただけます。
データの質がすべて
結局のところ、どの言語モデルを使うにしても、入力するデータの質こそが結果の正確さと信頼性を左右します。 選択した言語モデルとデータを効果的に結びつけるには、RAGが不可欠です。 ABBYYの検索拡張生成(RAG)機能は、言語モデルとシームレスに連携し、正確で文脈に即した最新の回答を提供します。 既存のナレッジベースと統合することで、ABBYYのRAGはAIに必要な文脈を与え、賢く信頼性の高い回答を実現します。
ABBYYなら、あなたの言語モデルの回答をもっと早く、もっと適切にし、ビジネスに合ったものします。詳細をお知りになりたい方は、ぜひ弊社のエキスパートにご相談ください。
