

専用AIが支える文書の分類と分割
文書分類は、文書の内容や文脈に基づいて種類別に自動識別・整理を行います。 インテリジェント文書処理プラットフォーム内で正しく分類されると、文書は、特定の文書タイプから正確かつ効率的にデータを抽出するために構築された、適切な抽出モデルに自動的にルーティングされます。
大量の文書を分類し、効率的に処理します
形式を問わず、あらゆる文書の処理をスピードアップ
画像ベースやテキストベース、定型文書や半定型、さらには完全な非定型文書まで、あらゆる形式に対応した文書分類モデルを使用して、手作業による分類を自動化します。200以上の言語に対応しています。ワークフローを劇的にスピードアップし、ヒューマンエラーのリスクを低減することで、業務効率を向上させ、チームが戦略的で価値のあるタスクに集中できるようにします。
大きなファイルを個々の文書に分割
請求書、注文書、契約書など、複数の文書タイプを含むファイルを自動的に分割し、より正確なデータ抽出を実現します。ABBYY IDPには、このタスクに対応するいくつかのオプションが用意されています。例えば、空白ページやバーコードで区切られたファイルを分割する簡単なテクニックを使用したり、一般的なファイルを管理するために事前に学習された文書分割モデルを選択したりできます。また、ニューラルネットワークに基づいた高度な機械学習アルゴリズムを使用して、文書の終わりと別の文書の始まりを決定するマーカーを認識する独自のカスタムモデルをトレーニングすることも可能です。
事前に訓練された分類モデルで100種類以上の文書を分類
当社の文書分類モデルは、画像処理、自然言語処理(NLP)、およびマルチモーダル機械学習アルゴリズムの強力な組み合わせを活用しています。運転免許証、銀行取引明細書、納税申告書、契約書など、文書の言語に関係なく、種類、外観、内容によって各文書が識別され、最適な処理のために正確に分類されます。
カスタム分類モデルのトレーニング
特定のビジネスニーズに合わせた文書分類モデルを簡単に作成し、トレーニングできます。船荷証券、保険金請求書、請求書、履歴書など、文書の種類ごとにいくつかの例を提供するだけで、モデルはすぐにそれらを認識し、正確に分類できるように学習します。ABBYYのローコードプラットフォームは、このプロセスを直感的で簡単にするため、技術的な専門知識がほとんどなくても文書分類を迅速に導入できます。
分類モデルの微調整と完全なカスタマイズ
モデルによるエラーを人間がレビューし修正するヒューマン・イン・ザ・ループ・プロセスを活用して、分類モデルを継続的に改善します。これにより、アルゴリズムが手動入力から学習し、時間の経過とともに精度が向上するフィードバックループが形成されます。その結果、より賢く信頼性の高い分類が実現し、一貫して適応し改善されます。

文書分類の仕組み
文書分類は、ビジネス文書の整理を効率化し、貴重な時間とリソースを節約します。ABBYYの専用AIは、機械学習や自然言語処理(NLP)などの高度なテクノロジーを活用し、IDのような定型フォーム、公共料金請求書のような半定型フォーマット、契約書のような非定型文書を含むあらゆる文書を読み取り、さまざまなデータを理解します。
- 準備
- 学習
- 分類
準備
文書を分類するカテゴリーを選択します。例えば、請求書、契約書、履歴書を別々のクラスに分類し、それぞれ異なるワークフローにルーティングできるようにします。
ファイルに複数の文書が含まれている場合、文書分割モデルはそれらを個別の文書に分割します。これにより、大きなファイルや複雑なファイルも適切に処理されます。
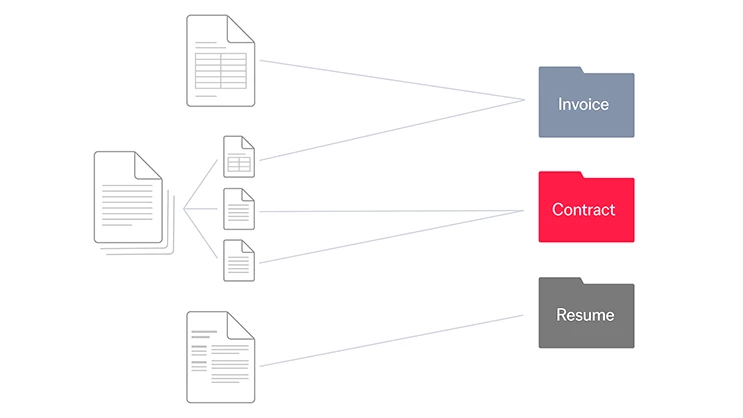
学習
クラスが定義されたら、各クラスに対するサンプル文書のセットを提供します。これらの例はAIアルゴリズムの学習データとなり、レイアウトやテキストコンテンツの特徴を基に文書クラスを区別する方法を学習します。この知識を活用することで、AIは受け取る情報を正確に識別できるようになります。
分類モデルの微調整は、この学習プロセスにおいて、関連するすべての文書を確実に取り込み、誤りを避けるために重要な役割を果たします。
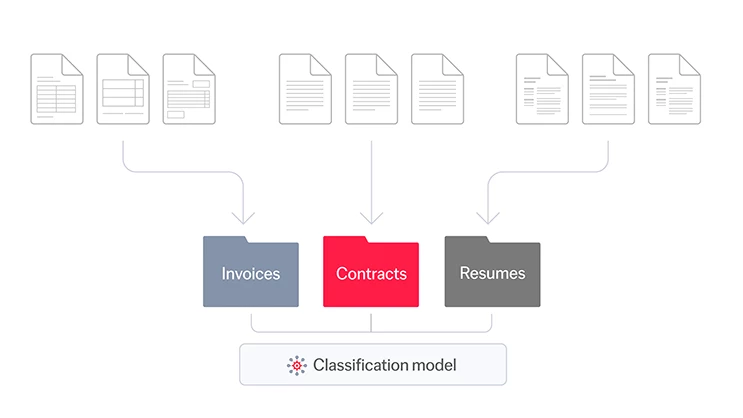
分類
これで分類モデルは学習され、使用準備が整いました。システムに入る新しい文書はすべて、モデルによって分析され、コンテンツの種類が特定されます。また、各項目には確率スコアが付与され、モデルがその選択にどれほど自信を持っているかを確認することができます。
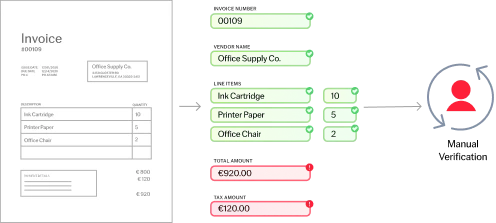
文書が特定されると、その文書から特定のデータ(ID番号、出荷日、受益者名など)を抽出するために設計された適切なデータ抽出モデルに分類され、ルーティングされます。その間、分類モデルは学習し続け、ヒューマン・イン・ザ・ループのプロセスを通じて精度を向上させていきます。このような手動チェックからのフィードバックは、時間の経過とともにモデルがより賢くなるのを助け、より正確な自動化につながり、人間の介入をより少なくします。
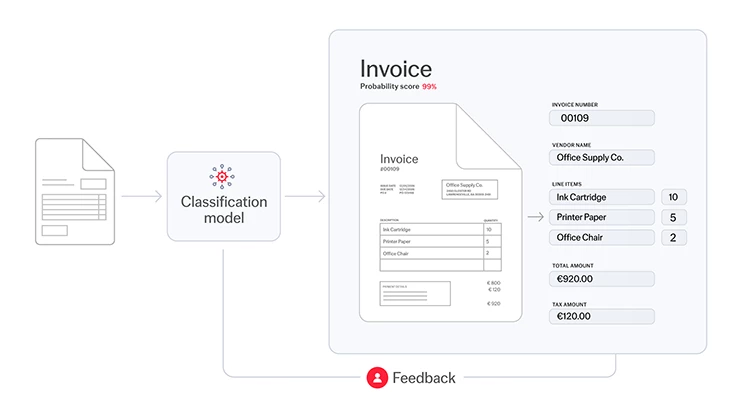
インテリジェント文書処理のパイプライン
文書のインプット
モバイルデバイス、電子メール、共有フォルダ、ネットワークスキャナ、API、事前に構築されたコネクタを介した業務システムへの直接接続など、さまざまなチャネルから文書を取り込み、文書がどのような形で組織に入ってきたかを問わず、ワークフローへのシームレスな統合を実現します。 この柔軟性により、多様なビジネスプロセスを効率的にサポートし、お客様固有のニーズに適応し、あらゆるエントリーポイントから業務を効率化することができます。
画像補正
文書内の画像の質は、照明の不良やモバイルカメラの歪みなどの問題によって大きく変化することがあります。また、パターン化された背景、保護マーク、フィールドマーク、ライン、ガイドなど、重要な情報を不明瞭にする複数の要素が問題となることもあります。
ABBYYのAI搭載画像補正アルゴリズムは、正確なデータ抽出のために各画像を最適化します。 AIが歪みを補正し、テキストを背景から分離することで、身分証明書、出生証明書、フォームなど、特に複雑で視覚的に多様な文書もクリーンアップでき、信頼性の高い結果と高いストレートスルー処理率を実現します。
OCR / ICR
AIは、以前は処理不可能と考えられていたコンテンツの読み取りや解釈能力を変革し、自動化のユースケースを劇的に拡大しました。 ABBYY IDPは、高度なAIベースの光学式文字認識(OCR)およびインテリジェント文字認識(ICR)技術を使用して、印刷されたテキストや手書きのテキストをデジタル化し、さらなる処理に備えさせます。 これらの技術は、表のような複雑な要素を含む文書全体の論理構造を認識することができ、文書の分類、データ抽出、デジタルフォーマットへの高品質なエクスポートを可能にします。
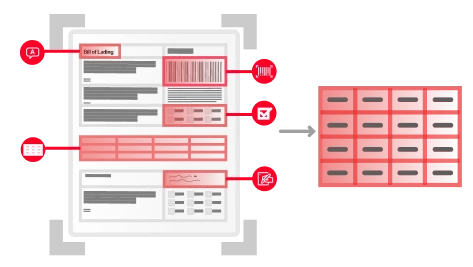
文書の分類とアセンブリ
AI分類モデルを使用して、テキストと画像の両方の特徴を分析しながら、文書を認識して整理するマルチモーダル学習を適用することで、文書の分類とルーティングを自動化します。 文書が分類されると、処理を行うためのAI抽出モデルが自動的に割り当てられます。 人間がループにインプットを行うことで、モデルはユーザーの修正から学習し、自動的に調整していくので、パフォーマンスは常に向上していきます。
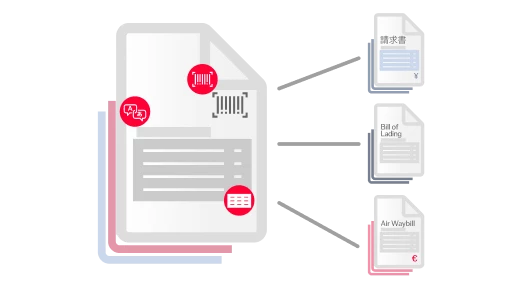
データの抽出と検証
人間の理解を模倣する高度なAIと機械学習を使用して、定型、半定型、非定型のビジネス文書からデータを抽出します。 ABBYY IDPは、200を超える言語の文書を読み取り、理解し、複雑な表、手書き、チェックマーク、バーコード、署名などを容易く処理します。
自動検証は、データベースと情報をクロスチェックし、組み込まれている検証ルールへの確実な準拠を保証します。 ローコードを基盤としているABBYYのアプローチでは、柔軟性が確保されています。ABBYY Marketplaceで入手できるな学習済みモデルを使用したり、これらのすぐに使用可能なモデルを組織固有のニーズに合わせて微調整したり、特定の文書に合わせてカスタムモデルを学習させたりすることが可能です。
LLM
特化型AIと大規模言語モデル(LLM)の柔軟性を組み合わせることで、ドキュメントワークフローを強化します。このハイブリッドアプローチにより、高度な要約、文脈に基づく推論、自動化されたコミュニケーションが可能となり、安全でスケーラブルな環境で新たな効率性を実現します。

ヒューマン・イン・ザ・ループ(HITL)と継続的学習
HITL(ヒューマン・イン・ザ・ループ)レビューにより、プロセスを改善し続けることが可能です。HITLレビューでは、対象分野の専門家が、使いやすいインターフェイスを通じて、抽出されたデータだけでなく、文書のクラスも手動でチェックし、修正することができます。 このオプションのステップは、100%の精度が要求される場合や、文書がAIモデルごとに設定された特定の検証ルールを満たさない場合に極めて重要です。 修正が行われるたびに、AIモデルは継続的な学習によって改善され、より正確になっていきます。
品質分析
ABBYY Document AIが提供する高度な品質分析により、文書処理のパフォーマンスを明確に把握し、ストレートスルー処理率の経時的な改善を追跡することができます。 アクション可能なインサイトとカスタマイズされたレコメンデーションにより、問題の根本原因を突き止め、モデルのデータ抽出品質を改善するための効果的な措置を取ることができます。それによりIDPワークフロー内で優れたビジネス成果を得ることが可能となります。

データ出力
ABBYY Document AIは、JSON、CSV、XMLなど、ニーズに合わせて必要な形式でデータを自動的にエクスポートします。 データは、シンプルなREST APIまたは下流プロセスに繋がる事前構築済みのコネクタを通じて、自動化システムやビジネスアプリケーションにシームレスに送信されます。
文書分類の詳細について学ぶ
文書分類—よくある質問(FAQ)
文書分類とは?
文書分類とは、ビジネス文書を正確かつ迅速に自動で分類するプロセスであり、エラーを削減し、時間を節約し、リソースを最適化するために自動化を活用します。
従来、文書が何であり、どこに分類すべきかを特定するには、多くの手作業や複雑なプログラミング、またはその両方が必要でした。通常、業界特化の専門知識を持つ訓練を受けた人が、各メールを読んだり、すべての法的文書を確認したりする必要がありました。今日、強力なAIツールが状況を一変させました。専門家が各文書を確認して処理方法を決めるのではなく、機械学習と高度なアルゴリズムを活用して、プロセス全体を効率化できるようになりました。
そのプロセスは以下の通りです。業務に入ってくるすべての文書は、AIツールでスキャンされ、分析され、あらかじめ定められたカテゴリーに分類されます。分類が完了すると、整理された文書は効率的な処理、データ抽出、またはさらにアクションを行うために適切な場所にルーティングされます。
文書分類を使って、会社固有の文書を扱うことはできますか?
はい。特定の文書がどのように識別され、処理されるべきかを定義するカスタマイズされた分類モデルや「スキル」を作成することで、独自のビジネスニーズに合わせて文書分類ツールを調整できます。
これらのスキルの学習プロセスは驚くほど簡単です。識別したいカテゴリーごとにいくつかのサンプルファイルを用意し、AIツールにこれらのサンプルを分析させ、視覚的レイアウト、テキストコンテンツ、印鑑や署名などの微妙なディテールに基づいて、異なる文書タイプを区別するよう学習させるだけです。
一度学習させれば、カスタムスキルはワークフローにシームレスに統合できます。エントリーする文書は、識別されたタイプに基づいてソートされ、ルーティングされます。この柔軟性により、定型フォーム、半定型請求書、非定型の往復文書など、どんな文書を扱う場合でも文書処理を最適化できます。
文書分類モデルを作成し、学習を行うには、どれくらいの技術的知識やプログラミング経験が必要ですか?
最良の文書分類ツールは、シンプルさを念頭に設計されており、直感的なローコード/ノーコードのインターフェースを提供することで、広範なプログラミング知識がなくてもカスタム分類モデルを作成し、学習させることができます。各クラスの例をいくつか提供し、正しいラベルやタグを割り当てることで、システムは将来的に類似の文書を識別・分類する方法を学習できるようになります。
今すぐ、デモをリクエストしましょう!
ABBYYのインテリジェントオートメーションのデモンストレーションを予約して、貴社の業務効率化やコスト削減、顧客サービスの向上など、さまざまな課題を解決する方法をご覧ください。
読み込み中...