Effective AI Agents Handle Well-Defined Tasks, Not Jobs
by Nick Carr, Director of Pre-Sales
There’s a strong narrative, at the moment, that AI agents can replace entire roles. The promise is simple: fewer people, lower costs, faster decisions. But, replacing a role isn’t the same as redesigning the work.
When agents are deployed without clear boundaries, defined tasks, or controlled inputs, costs climb quickly. What starts as a single prompt can turn into a chain of reasoning steps, tool calls, memory lookups, and follow-on workflows. Tokens get consumed at every stage.
At the same time, outcomes begin to vary. Give an agent too much freedom, and it will try to solve everything. Without guardrails, you’re not automating a process; you’re letting an intelligent system explore one. In some cases, organizations are now finding that the operational cost of uncontrolled agent workflows rivals, or even exceeds, the cost of the people they were meant to replace. The issue isn’t that agents aren’t capable. It’s that capability without structure doesn’t scale.
Let’s say we want to replace a role with an agent. A job entails much more than one task—it’s a collection of checks, decisions, validations, and escalation paths. It includes the obvious steps in the SOP, as well as the workarounds that never made it into the documentation. In reality, people constantly deal with exceptions. They fix data issues. They make judgement calls. They handle edge cases that sit just outside the “happy path.” Many of those decisions aren’t formally captured anywhere; they live in experience.
So, when we talk about replacing an entire role, we’re not replacing a single workflow. We’re replacing a network of small decisions across multiple processes. That’s where complexity grows quickly. Instead of replacing the role completely, the more effective approach is to separate it: break down what the human is actually doing into specific tasks. Define the inputs. Define the outputs. Define the boundaries.
When an agent is given a narrow, well-defined task, with clear parameters and controlled data, it can perform consistently. When it’s asked to “be the role,” without structure, you end up automating the chaos around the process instead of the process itself.
Defining agent roles in a KYC use case: mortgage onboarding
This is exactly the well-defined approach I took when I built an agent-driven KYC (Know Your Customer) process focused on mortgage onboarding for our recent ABBYY Sales Kick-off Hackathon challenge. I deliberately avoided trying to replace the role. Instead, I broke the process down into clear tasks with a key objective/outcome. The goal was to automate the delivery of the results to the internal case team with clear actions and to communicate back to the customer applying for the mortgage.
While thinking about where an agent should sit in a process, I focused on a few key design questions:
- Where does the agent add value?
- What information should it have access to?
- When should it act, and when should it not?
- What decisions is it actually responsible for?
The KYC process is a good example to explore this properly because it’s not simple. There are multiple document types, different data sources, edge cases, and a mix of structured and unstructured information. It’s exactly the kind of scenario where people assume an agent can “just handle it.”
Instead of handing everything to the agent, I structured the process in stages.
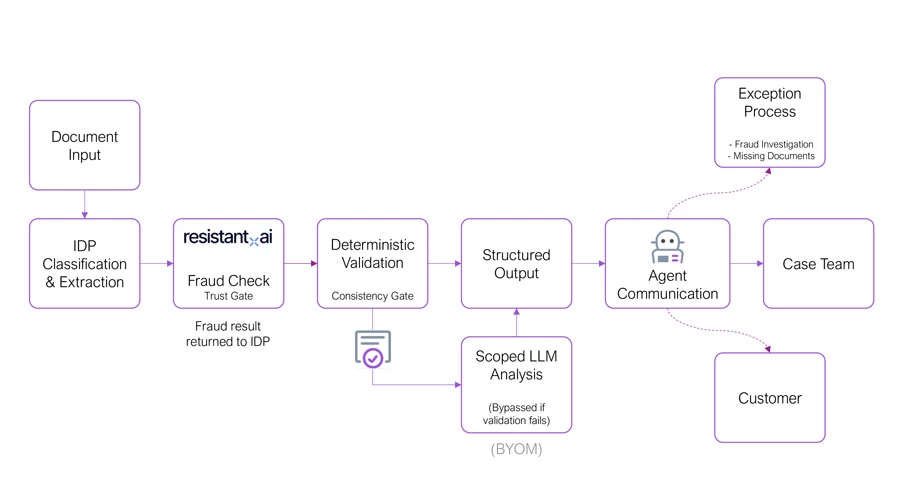
1. First, establish document truth.
Using IDP, the documents are separated, classified, and the key data is extracted. This gives a reliable, structured view of what has actually been submitted. No assumptions, no generation; just what is in the documents.
2. After extraction, introduce an additional control point: fraud detection.
Before any further processing, the documents are assessed to determine whether they have been tampered with or artificially generated. If the response is not clean, the process does not continue as normal. Instead, it follows an exception path.
In this scenario, the downstream validation and LLM steps are skipped, and the agent is used to trigger a separate workflow, for example, notifying a fraud team to begin an investigation. While there is no value in analyzing or reasoning over data that cannot be trusted, there is still value in acting on that outcome.
3. Next, validate that data.
Before any reasoning happens, deterministic checks are applied. Do the documents belong to the same person? Are the bank statements complete? Do the payslips align with the transactions? If these checks fail, the process does not stop. Instead, the outcome changes. A structured summary is created to highlight what has failed. Missing documents, mismatched data, incomplete submissions. This is still useful, and it is grounded in verified extraction.
In this case, the LLM step is bypassed. There is no point performing deeper analysis on incomplete or inconsistent data. The agent is then used to act on that validated state, communicating clearly to both the internal case team and the customer on what needs to happen next.
4. Introduce (or not introduce) an LLM.
Only when the data is both valid and consistent do I introduce an LLM, and even then it is scoped. In this case, it is used to analyze transaction data and summarize financial behavior. No personal data is sent, and it is not making the final decision.
At this point, the process has moved from raw documents to validated, summarized information. The key aspect is that the process always produces a structured outcome. Whether the application passes, fails validation, or is flagged for fraud, the format is consistent, and the next step is clear. The system produces a defined state. That is what the agent acts on.
The agent does not:
- See the documents
- Perform extraction
- Validate data
- Run underwriting logic
It receives a clean, structured summary and performs a single task, communicating the outcome.
This approach works because each part of the process has a clear purpose.
- IDP establishes the data.
- Fraud detection checks trust.
- Underwriting analysis adds context.
- The agent’s role is only communication and acting on verified, determined data.
That keeps the agent’s role grounded. It is not being asked to figure everything out. It is given a specific task, with specific inputs, and acts on them. This is not just about adding guardrails to an agent. It is about designing the system so the agent operates within clear boundaries from the start. And cost is controlled because each component is only used when it is needed.
The IDP layer orchestrates the flow and performs deterministic validation. Fraud detection is applied to all documents to ensure they can be trusted. The LLM is only invoked when the data is complete and consistent. And when the LLM is used, it operates on structured data, not raw documents. Only the relevant transactional data is passed in, which keeps token usage low and avoids unnecessary processing.
When the agent is invoked, it receives a consistent, structured input. Whether the outcome is approve, decline, or incomplete, the format is the same. That consistency removes ambiguity and leads to predictable behavior.
Each stage has a defined responsibility. Extraction, validation, reasoning, and communication are separated and controlled. This makes the process easier to understand, test, and govern, and makes it clear how each outcome was reached.
The process also handles real-world scenarios. Missing documents, inconsistent data, or fraud do not break the flow. The system adapts and still produces a usable outcome, which the agent can act on.
Additionally, this approach scales. You can add more document types, more validation checks, or extend the use of the LLM without changing the role of the agent. The key is surfacing the right data, in the right format, at the right time.
The real value of an agent is not determined by what the agent can do. It is determined by the design of the system to give it the right information to act on. Agents do not remove the need for architecture. They make it all the more important.