Generative AI can perform impressive tasks, but it has a well-known flaw: It sometimes “hallucinates” and makes up answers that sound right but aren’t.
To get the benefits of large language models (LLMs) without the misinformation, many businesses are pairing them with another AI technology: retrieval-augmented generation (RAG).
RAG helps LLMs give more accurate, trustworthy answers by linking them to external data sources with relevant information. Agentic RAG takes this technology further to also plan, decide, and act on those answers. To put it simply, RAG retrieves facts, while agentic RAG uses those facts to make decisions and take actions.
Let’s take a look at how both traditional RAG and agentic RAG work, what their benefits and limitations are, and how to choose the right one for your business.
Jump to:
Understanding how traditional RAG works
Understanding how agentic RAG works
RAG vs Agentic RAG: Key differences at a glance
Why agentic RAG alone can’t work in isolation
How ABBYY builds a strong foundation for RAG and agentic RAG
What is RAG?
RAG is an AI approach designed to make LLMs more accurate and reliable. Instead of relying only on the data they were trained on, RAG systems connect LLMs to trusted documents or databases to pull in up-to-date, relevant materials before generating a response. This way, LLMs can ground their answers in real evidence and give more reliable, context-aware answers.
The main benefits of RAG include:
- Enhanced contextual understanding: By reasoning across multiple data sources, agentic RAG connects related information for more comprehensive insights.
- Improved accuracy: Grounded in structured, validated data, RAG produces responses that are more precise and aligned with enterprise knowledge.
- Reduced hallucinations: Every output is based on retrieved, verifiable information, so the risk of fabricated or incorrect content is significantly lower.
Key components of RAG
RAG systems rely on a number of components that work together:
- Embedding model: An embedding model converts words, sentences, or documents into sets of numbers called vectors. These vectors capture context and relationships between ideas, so systems can recognize meaning and relevance, even when different words are used.
- Vector store: A vector store houses the vectors and enables semantic search, retrieving information based on meaning and context. This lets RAG systems find the most relevant content from a pre-indexed knowledge base.
- Retriever: When a user submits a question, a retriever searches the vector database to identify and rank the most contextually relevant documents.
- Prompt construction and generator: The relevant information gets combined with the user’s original question and is sent to the LLM. Using both its general training and the retrieved facts, the LLM then generates a final response.
Challenges and limitations of RAG
Traditional RAG, however, comes with some limitations:
- Static retrieval: RAG relies on a fixed, pre-indexed knowledge base. It can’t dynamically update in real time, so responses can get outdated.
- Limited contextual understanding: RAG must receive accurate and organized data to function well. If the information it's given is disconnected or incomplete, RAG’s outputs will not be as accurate.
- No multi-step reasoning: Traditional RAG retrieves and summarizes information, but can’t reason or plan across several steps to make decisions or take actions based on what it finds.
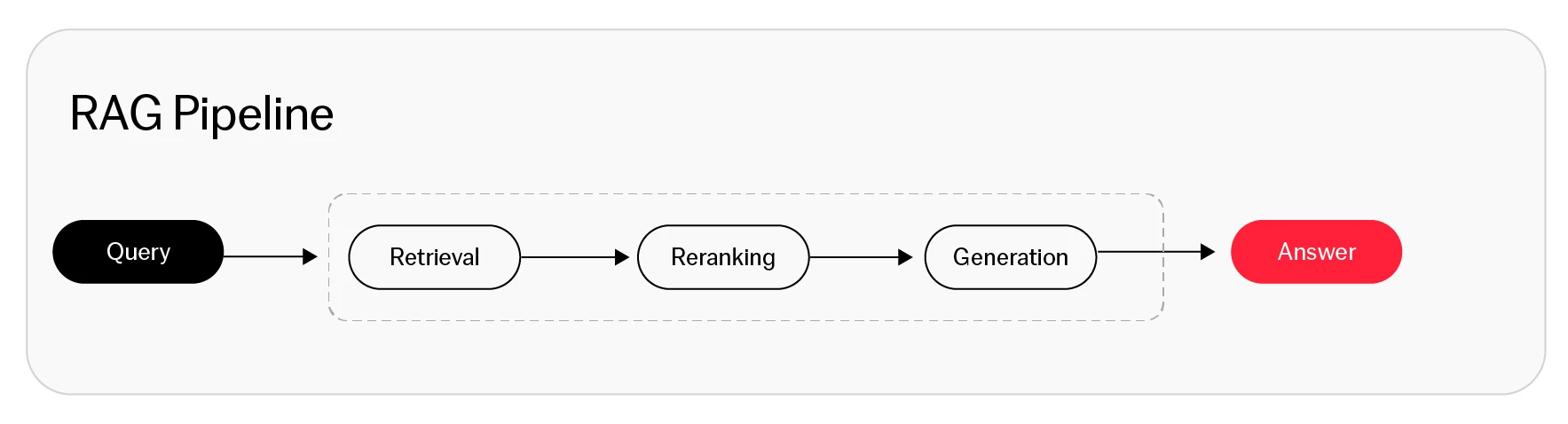
Understanding how traditional RAG works
Here’s how the traditional RAG workflow typically works:
- User prompt: A user asks the RAG system a question or gives it a prompt.
- Retrieval: The system combs through its knowledge base to pinpoint and draw from the most relevant, trusted information.
- Integration: The retrieved information is combined with the user’s original prompt to create an augmented prompt: an input that includes accurate and contextual background.
- LLM output: The LLM uses this prompt to generate a response that’s more accurate and traceable to its original sources.
What is agentic RAG?
Agentic RAG strengthens LLMs by not only grounding their responses in external, verifiable sources but also adding the ability to reason, make decisions, and take action based on what they learn.
Basically, while traditional RAG simply gives responses, agentic RAG can also act on these responses like an active participant in problem-solving.
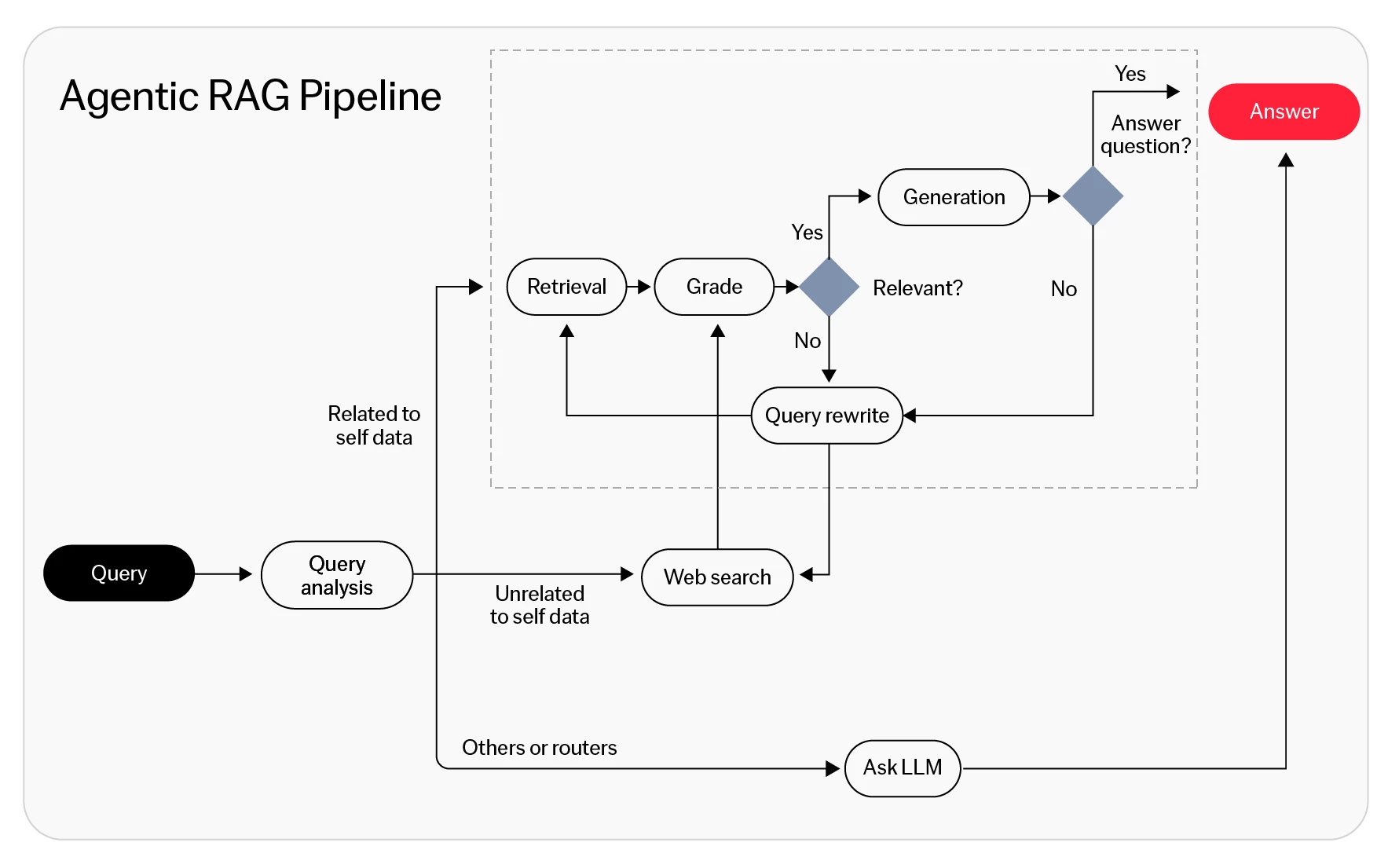
Understanding how agentic RAG works
Agentic RAG adds reasoning, decision-making, and action to the traditional RAG workflow:
- User prompt: As with traditional RAG, the agentic RAG process begins with a user question or prompt that defines the task for the system to solve.
- Retrieval: The model searches its knowledge base using semantic retrieval to find the most relevant information, just as in traditional RAG.
- Reasoning and planning: The agent interprets what it finds to decide if the retrieved data is sufficient or if more context is needed to deliver a complete and accurate answer.
- Iterative retrieval: If more context or data is required, the agent runs more searches to refine or validate facts until it reaches a confident understanding.
- Augmented prompt: The agent uses the information it's gathered to come up with a refined prompt for the LLM.
- LLM output: The LLM generates a response or action plan that’s grounded in the retrieved information.
- Validation: The agent checks the output against trusted sources or business rules and triggers next steps as needed.
RAG vs Agentic RAG: Key differences at a glance
Traditional RAG improves LLM accuracy, while agentic RAG goes further to identify gaps, retrieve additional data when needed, validate information, and take action.
| RAG | Agentic RAG | |
|---|---|---|
| Definition | AI architecture that improves LLM performance by connecting them to external knowledge sources | Advanced RAG architecture that incorporates intelligent agents to reason, plan, validate, and act |
| Use case | Knowledge retrieval, FAQs, summarizing information | Complex tasks like: decision support, automated workflows, multi-step problem solving |
| Adaptability | Relies on a pre-indexed knowledge base and reacts only to user prompts | Performs multiple searches to refine results as necessary |
| Accuracy | Grounds responses in external data to improve precision | Further improves precision by validating and cross-checking responses |
| Focus | Grounds responses in trustworthy information to reduce hallucinations | Uses grounded knowledge to reason, decide, and take action |
| Limitation | Dependent on the quality and scope of its data sources; limited to retrieval and summarization | Dependent on the quality and scope of its data sources |
| Efficiency and cost | Generally faster and less resource-intensive | More capable, but also more expensive and complex to design and operate |
In short, RAG helps LLMs provide context-grounded answers quickly, while agentic RAG adds reasoning and validation for more accurate, reliable outcomes.
Why agentic RAG alone can’t work in isolation
As versatile and powerful as agentic RAG is, used on its own, the technology comes up against limits:
- Dependence on data quality: Even the most capable agent can act only on the information it has. If the information given to an agentic RAG is inconsistent or unstructured, you can get unreliable outcomes.
- Increased cost and latency: Repeated data retrieval helps make LLM outputs more accurate, but the extra work also requires more processing power and time. That, combined with the resources needed for agentic RAG’s multi-step reasoning, can increase costs.
- Higher complexity: Automating end-to-end workflows requires coordinating agents and platforms with business systems. This can be a challenge if the technologies aren’t compatible or don’t work easily with each other.
How ABBYY builds a strong foundation for RAG and agentic RAG
Strong data quality is the foundation of any successful RAG system, traditional or agentic. This is what ABBYY Document AI provides. By turning unstructured content into clean, structured, and semantically rich data, ABBYY gives RAG models a trusted base of truth to reason from. Agentic RAG delivers intelligence, but ABBYY delivers the reliable data that makes that intelligence work.
By automating document extraction and structuring, ABBYY also reduces the noise and redundancy that slow down retrieval and reasoning. Additionally, ABBYY simplifies the technical side of deploying agentic RAG by offering structured data pipelines and API-based integrations.
To see how ABBYY Document AI augments RAG, watch this three-minute demo video. To explore how ABBYY can strengthen your RAG or agentic RAG initiatives, connect with one of our experts.
