Streamline document searches
Turn all legal documents into searchable, actionable information at your fingertips.
Legal document automation


Many legal teams see their efficiency impeded by paper and static scanned documents, making it difficult to access and use information efficiently in an increasingly digitized business environment. Time and money slip away when teams struggle to access, use, and share critical information locked away in these documents.
ABBYY empowers legal professionals to focus more on practicing law and less on hunting for document-based data. Retrieve client and internal information more efficiently while ensuring that your team never misses an opportunity to create business value from your data.
Find out how ABBYY helps legal professionals focus more on practicing law by automating the input, processing, and analysis of legal documents.

Learn how to handle legal documents like top performers, from making every document searchable to sharing documents securely.

ABBYY Vantage’s no-code approach lets citizen developers rapidly advance digital transformation, no specialized training required.
Find out how ABBYY helps legal professionals focus more on practicing law by automating the input, processing, and analysis of legal documents.
Learn how to handle legal documents like top performers, from making every document searchable to sharing documents securely.
Find out how ABBYY helps legal professionals focus more on practicing law by automating the input, processing, and analysis of legal documents.
Learn how to handle legal documents like top performers, from making every document searchable to sharing documents securely.





ABBYY’s intelligent document processing solution uses purpose-built AI to automate the input, processing, analysis, and organization of contracts, briefs, and other legal documents.
Vantage document skill to classify California Real Estate Forms and extract key fields.

The Lease Agreement (US) document skill for ABBYY Vantage extracts data from US lease agreements.

Vantage document skill for extracting key fields for Certificate of Vehicle Title for all USA states.

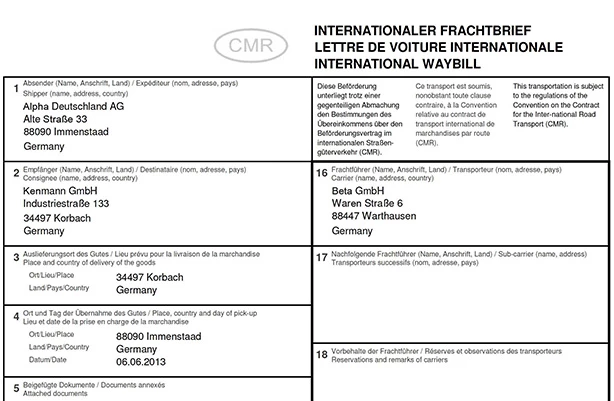
The International Consignment Note (CMR) skill is a purpose-built AI model, that extracts data from international consignment notes in four languages - English, German, French and Spanish.
in labor costs saved per document revision
trust deeds reviewed in seconds
documents turned into fully editable, searchable formats

Find out how ABBYY’s intelligent automation and best practices can enhance generative AI reliability by addressing key biases.
Get answers to your most frequently asked questions about IDP, along with insights on how you can use IDP to transform your business.
Unlock new value from your contracts with AI-powered insights that streamline compliance, enhance supplier relationships, and optimize revenue.
Find out how ABBYY’s intelligent automation and best practices can enhance generative AI reliability by addressing key biases.
Get answers to your most frequently asked questions about IDP, along with insights on how you can use IDP to transform your business.
Unlock new value from your contracts with AI-powered insights that streamline compliance, enhance supplier relationships, and optimize revenue.
Find out how ABBYY’s intelligent automation and best practices can enhance generative AI reliability by addressing key biases.
Get answers to your most frequently asked questions about IDP, along with insights on how you can use IDP to transform your business.
Unlock new value from your contracts with AI-powered insights that streamline compliance, enhance supplier relationships, and optimize revenue.
Schedule a demo and see how ABBYY intelligent automation can transform the way you work—forever.