Back to ABBYY Blog
Field-level OCR. What is it for?
February 28, 2013
February 28, 2013

In the API Cloud, we single out two types of OCR, full-page OCR and field-level OCR. They have different pricing, but there are also fundamental differences between the two. Each approach serves its own purpose. Unfortunately, not all developers who are new to OCR are aware of these differences, and often have to learn by trial and error. Even some big players in the Data Capture industry still adhere to full-page OCR only, ignoring field-level OCR. Their applications were developed many years ago and it would cost them a pretty penny to rework the entire architecture and the user interface and to re-educate their partners. However, the price they pay for their unwillingness to change is lower quality of OCR.
A need for field-level OCR arises each time we want to extract some useful information from a document. This OCR scenario is commonly known as Data Capture. Suppose you have received an invoice and need to capture the name of the company, the amount you need to pay, and the date by which the payment is due. Remember that an invoice may contain several amounts from which your Data Capture program should select the right one. You won’t be very happy if the program mistakes a telephone number for the amount you need to pay.
The typical processing steps in this scenario are shown in the diagram below:
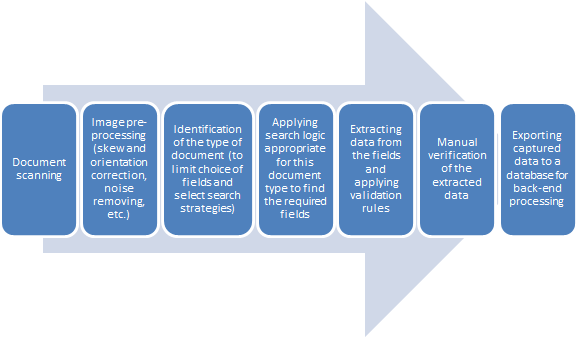
Depending on the type of document being processed, different methods may be used to search for data fields. In the simplest case of machine-readable forms, where identical data are always placed in exactly the same location on each copy, all the program needs to do is find the right template which tells it where to look for the data. Next, the template is matched against a filled-out form and the data are extracted. To make the matching procedure easier for the program, visual anchors are printed on each form, like the black squares in the picture below:
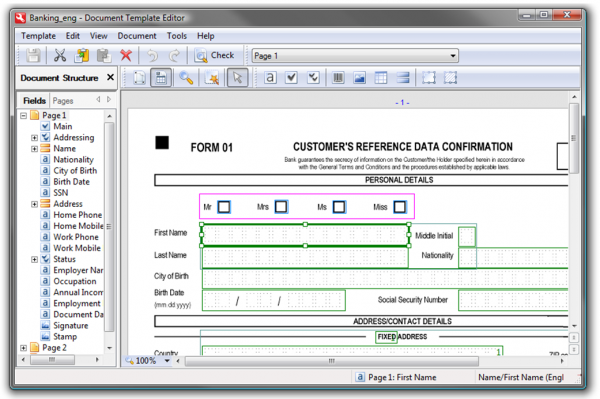
However, this method will not work for documents like invoices, because their layout will vary from invoice to invoice. More sophisticated techniques are used in this case. For instance, the program may look for words like “Invoice #” and “Due date:” and use them as a starting point to look for zones with useful data. In order to do this, the program will also rely on some knowledge of how this particular company prefers to organize information on its invoices.
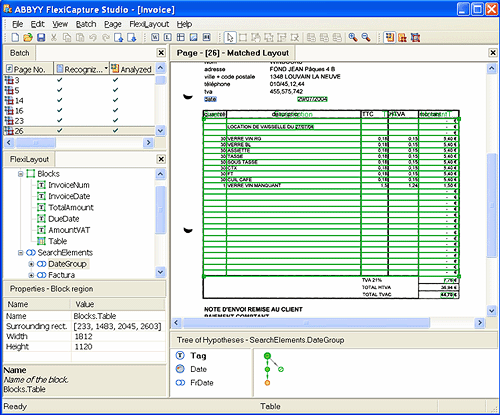
Once the program has some idea where the relevant data are located (the most advanced systems, like FlexiCapture, will generate several hypotheses about the exact locations), it decides on how to extract them.
Let us assume that the program has correctly identified a “Total amount” field, which contains the money to be paid, not a telephone number. But errors are still likely to occur. For instance, the program may fail to notice the comma and the point in, say, “$1,000.00” and interpret it as “$100000”, prompting us to pay a hundred grand instead of one thousand dollars. When money is involved, the right question to ask is “How much time and human resources will it take to manually verify the captured data?”, not the abstract question of “What’s the error percentage of the OCR module?” In other words, the quality of the technology is measured in terms of human labour required to verify the data. Error percentages are important, and the fewer errors a system makes, the less time and effort you need to correct them. But equally important is how the program communicates with the human verifier, telling him or her which characters look suspicious or have been captured with a low degree of confidence. This aspect is so important that it merits a separate article.
As I said earlier, many Data Capture solutions still have no separate field-level OCR step. These may be termed one-pass solutions, because OCR is performed only once. In these solutions, the text obtained with full-page OCR is used to identify the type of the document and to find the data fields, and then this very text is served up as the captured data.
However, we believe that at this point, it makes every sense to do OCR on these specific fields once again, now equipped with the knowledge we gained at the previous stage. The idea behind is that by limiting the range of possible values we may greatly improve the quality of OCR and better identify “suspect” characters. This has a positive effect on the key characteristic of the system, which is the amount of manual efforts required to correct them.
Consider this for example. If we know what type of field we are about to capture, we can tweak the following to our advantage:
In principle, all this tweaking is done by disabling the automatic routines used in all advanced OCR software, which will work fine in almost all cases. But as we said earlier, in Data Capture “almost” is just not acceptable. For this reason, captured data must be first validated by means of logical rules and then manually verified by human operators — sometimes more than once, because humans, unfortunately, "almost never err".
By way of example, consider the receipt shown in the picture below.

You will notice that this document is a nightmare of any OCR program. Some letters and digits are jammed together while others are too thin and sketchy for a computer to recognize.

Despite all this, today’s OCR software can do a decent job of recognizing stuff like this. If you open this picture in ABBYY FineReader 11 and apply the default OCR settings, the program will find some method in this madness. Not so bad on the whole, but there are lots of OCR errors as well. For example, one fragment which are particular interest to us, the one that lists services and prices, has been interpreted as “$o.ce” instead of “$0.00”.

Some people new to OCR may wonder “Why?” — because anyone can see that the line should be read as “$0.00”! Alas, only humans will immediately know that this is a receipt with digits, not gibberish, in the third column. But how an innocent OCR program should know this? When it sees strings like “5UAMM575” in the first column, it expects something similar in the others. FineReader does not do any shopping, and its default settings have been selected to accommodate texts of many different types — receipts, newspapers, glossy magazine articles with fancy layouts, and many more. The problem can be solved by having two OCR stages. First, the program does OCR, understands that it is dealing with a receipt, and notes that the third column in AJ Auto Detailing Inc. receipts contains only amounts in the format $XXX.XX, no letters. Therefore, when it does OCR a second time, it will be aware of the restrictions that apply (these may be specified by using a regular expression, for example). This time the program will not be tempted to recognize sketchy digits as letters.
In the case of one-pass OCR, however, the program has no chance to adjust its algorithms, forced to rely on the “one-size-fits-all” settings, which are selected to work not only for the data fields at hand, but also for any other text in all other possible types of documents. This is a serious limitation, which developers try to overcome by devising smarter post-processing and validation rules, by making manual verification more efficient, etc. All such techniques are very useful, no doubt, but when we have a good opportunity to reduce the number of OCR errors, why not use it?
If, besides the prices, we also need the products names, we can use a dictionary of products names compiled for this particular supplier. This will help the program to capture the products correctly. Note, however, that before the program can select the right dictionary it needs to know the supplier. If it uses all of the product dictionaries that are available to it, it will have too many alternatives to select from and the likelihood of error will increase.
In the once-pass vs. two-pass OCR debate, longer processing times are often cited as an argument against a second OCR step. In fact, a second OCR pass reduces processing times, and here is how. When a program does OCR a second time, it process only a small fraction of the document, with a lot of the default settings disabled in favour of the more precise manual settings. If the OCR is done on a local server, the time required for the second OCR pass is infinitesimally small compared to the first pass. Besides, in the two-pass approach, the first OCR pass is only used to establish field locations and to identify the document type, both processes being not sensitive to OCR errors as they use fuzzy matching algorithms. The text extracted in the first OCR pass will not make it directly into the final results, so we can use fast OCR recognition in the first step, which is two or more times faster than thorough OCR.
It is true that in the case of cloud OCR the end-user application will need to communicate with the server twice. But higher OCR quality that can be achieved this way is worth the effort.
