Capture all kinds of content
Equipped with AI and ML capabilities, our AI Document Skills can understand content, context, relationships, and entities within structured as well as unstructured documents (printed & handwritten).
Mailroom Automation


Shorten your processing and response times with automated mail classification and routing for faster responses to customer inquiries.

PAUL WALSHE, Partner at Moore Blatch
ABBYY Vantage integration with Graph API is a module that sends email from ABBYY Vantage using Microsoft Outlook email account.

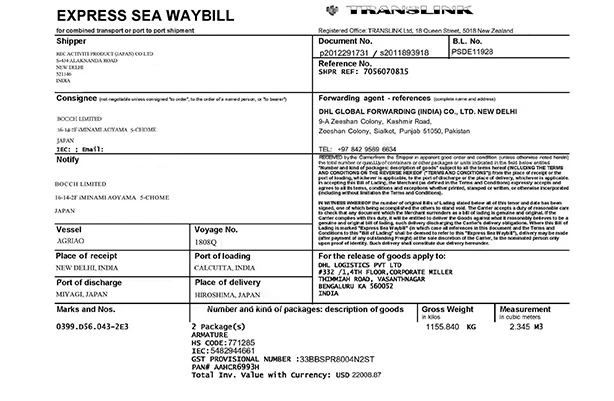
The Vantage Sea Waybill document skill is a pre-trained AI model that extracts data from sea waybills.
The ABBYY Vantage Automated Email Response skill enhances productivity by enabling organizations to automatically process incoming emails, extract key information, and generate contextually accurate responses.

The ABBYY Vantage Connector for Make.com simplifies adding Vantage Skills to Make.com workflows, enabling AI-powered OCR and data extraction for automated document processing.
ABBYY’s Intelligent Document Processing platform provides the most comprehensive, robust, and technologically advanced solution for enabling customers to automatically identify, transform, and leverage process-ready content locked within documents.






Schedule a demo and see how ABBYY intelligent automation can transform the way you work—forever.